
In this blog post, we review a list of pretrained language models, including BERT, Transformer-XL, XLNet, RoBERTa, DistilBERT, ALBERT, BART, MobileBERT, ELECTRA, ConvBERT, DeBERTa, and BigBird.
BERT
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin et al.
Description and Selling points
BERT is the first bi-directional (or non-directional) pretrained language model. It uses self-supervised learning to learn the deep meaning of words and contexts. After pretraining, the model can be adapted to different tasks as well as different datasets with minimal adjustments.
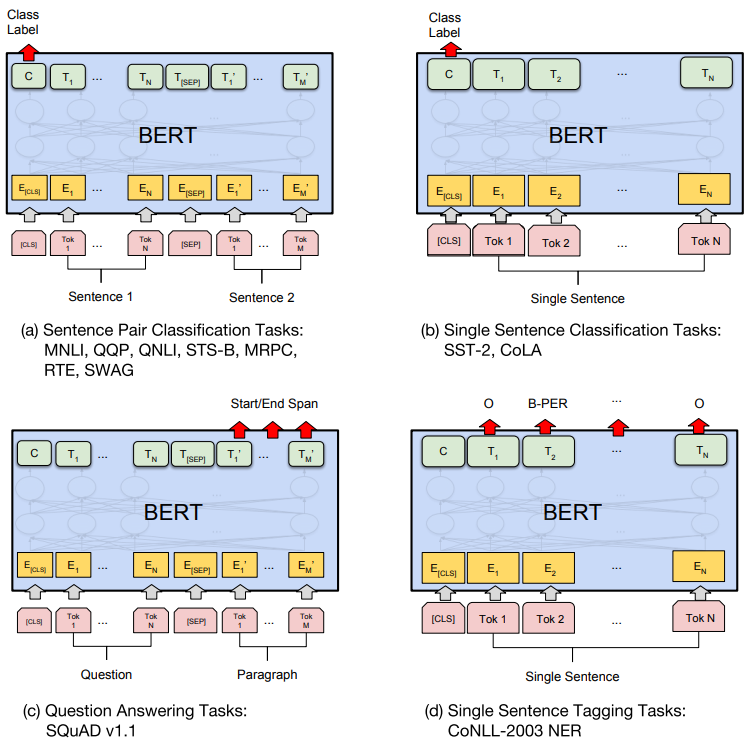
At the time it is published, BERT not only outperformed state-of-the-art models on 11 tasks (including GLUE and SQuADs) by a large margin but also marked the era of language model pretraining.
Architecture
BERT reuses the encoder block from the Transformer. The  uses 12 encoder blocks, while this number for the
uses 12 encoder blocks, while this number for the  version is 24. Note that, while these two versions also have some other differences in layer sizes, the fundamental architectures are the same.
version is 24. Note that, while these two versions also have some other differences in layer sizes, the fundamental architectures are the same.
| | |
|---|---|---|
| No. encoders | 12 | 24 |
| Embedding dim | 768 | 1024 |
| Attention heads | 12 | 16 |
| No. parameters | 110M | 340M |
Training
BERT is pretrained on 2 tasks: Masked Language Modeling (MLM) and Next Sentence Prediction (NSP).
- For MLM, a random 15% of the text is chosen to be masked. Over these tokens, 80% is replaced with
![[MASK]](https://tungmphung.com/wp-content/ql-cache/quicklatex.com-7b5061b8ae13770c6d7b7b923511ec57_l3.png "Rendered by QuickLaTeX.com") , 10% is replaced with a random token from the alphabet, and the remaining 10% is kept the same. The objective of the model is to recover the original texts from this masked version.
, 10% is replaced with a random token from the alphabet, and the remaining 10% is kept the same. The objective of the model is to recover the original texts from this masked version. - For NSP, BERT takes as input 2 sentences, denoted as A and B, its mission is then to predict if B is actually the next sentence after A in the corpus. This task aims to strengthen BERT’s ability to reason across sentences, which will then be helpful for tasks like Question Answering and Natural Language Inference.
Data, Hardware, Speed
BERT is trained on 16GB of text data, which consists of 3.3B tokens.
was trained with 16 TPU chips while was trained with 64 TPU chips. Each takes 4 days to complete.
Other information
While BERT is definitely a masterpiece, it also poses a number of limitations. Here, we briefly mention some of the most important ones. All of these will then be addressed in more recent work (that we will discuss in the next sections).
- There is discrepancy between pretraining and finetuning because of the token. The token appears many times in pretraining but not in finetuning.
- During pretraining, BERT predicts each masked token independently of the others, which is an oversimplification, leading to suboptimal performance.
- BERT learns from only 15% of the input tokens.
- The Next Sentence Prediction task is too weak compared to Masked Language Modeling.
- The context length of BERT, which is fixed as 512, is small for some tasks.
- In the Transformer architecture, the Embedding dimension size must be set equal to the Hidden layer dimension size, which is a design constraint that does not have any semantic reason.
- The masking of training data is done once and reused for all epochs. This can be improved by dynamic masking at any epoch.
- The training data size is small, only 16GB of text.
Transformer-XL
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, Dai et al.
Description and Selling points
Transformer-XL is an autoregressive model (not bi-directional like BERT). It has 2 main advantages over its competitors:
- Transformer-XL can learn longer context. The authors claim that it can learn dependency that is 450% longer than vanilla Transformer, thanks to the ability to handle the problem of context segmentation.
- It also enhances the evaluation speed by 1800+ times.
These advantages result in State-of-the-Art performance in long-context datasets (e.g. WikiText-103, enwiki8), even short-context datasets (One Billion Word dataset), and small datasets (the Penn Treebank with 1M training tokens).
Architecture
Transformer-XL reuses the hidden states obtained in previous segments for the next segment, which, in other words, introduces the notion of recurrence into the attention-based architecture. This additional context is added to the key and value of the attention mechanism to make it aware of further information from the past.
To make this works, the authors also need to make use of Relative Positional Encoding to replace the Absolute Positional Encoding normally used in Transformer models.
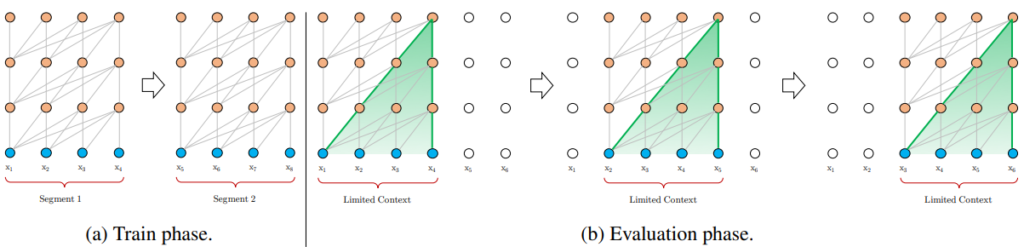

With the Transformer-XL model, more context is included.
Training, Data, Hardware, Speed
Transformer-XL was not designed as a to-be-reused pretrained language model. It trains on different datasets for different tasks. Thus, the information about hardware and speed is not relevant here, as it cannot be compared against other pretrained models.
Other information
The ideas from Transformer-XL are then be adapted by XLNet, the model we are going to introduce next.
XLNet
XLNet: Generalized Autoregressive Pretraining for Language Understanding, Yang et al.
Description and Selling points
XLNet is a very interesting model that builds upon both BERT and Transformer-XL (i.e. bi-directional and autoregressive, respectively). It handles some of the weaknesses of BERT, including:
- The assumption of independence between masked tokens. With XLNet, the prediction of one masked position can depend on other masked positions (similar to the autoregressive style).
- The discrepancy of having tokens during pretraining but not during finetuning. XLNet does not replace tokens with .
- The short context limitation. XLNet employs the recurrence mechanism and Relative Positional Encoding from Transformer-XL to improve performance on long context.
Using the same model size and pretraining data, XLNet outperforms BERT in 20 tasks, achieving the SOTA at the time.
Architecture
XLNet uses a similar architecture as BERT and integrates the improvement from Transformer-XL (the recurrence mechanism and Relative Positional Encoding).
Training
XLNet was pretrained with the autoregressive style. However, in contrast to traditional autoregressive models which always lose the context of 1 side of the predicted position (e.g. the GPT model only uses the preceding tokens to predict the current token, while information from the successive tokens is ignored), XLNet still manages to learn from both sides.
The task is termed Permutation Language Modeling. That is, the (virtual) order of the tokens is randomly permuted, and each token is then predicted using the preceding tokens in that virtual order. We also call this order the Factorization order. Take a look at the below figure for illustration.
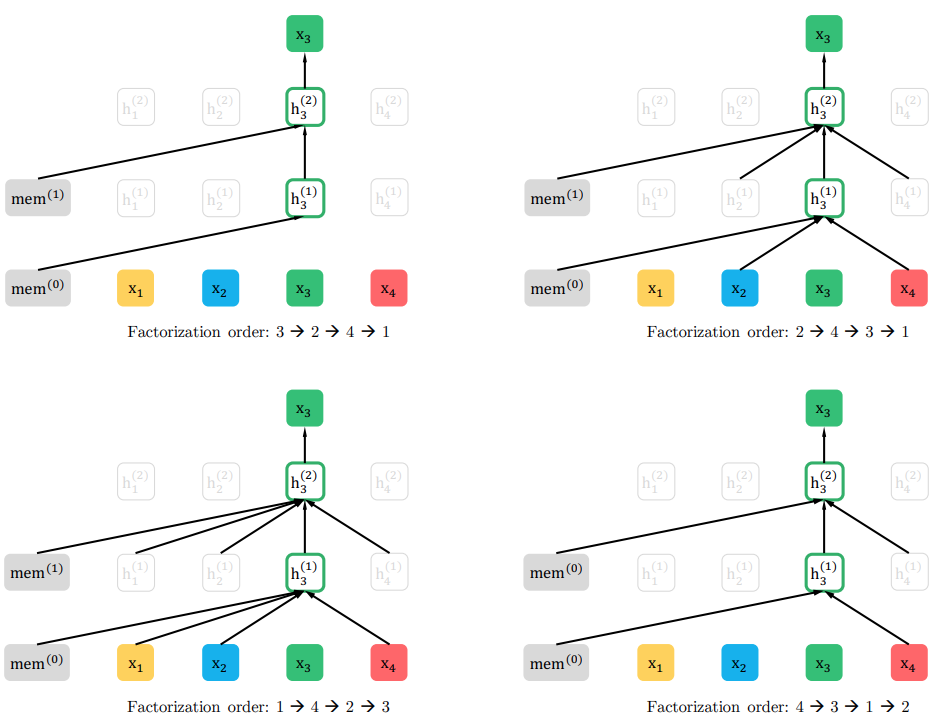
 given different factorization orders. In any situation, is only predicted using the tokens that come before it in the factorization order.
given different factorization orders. In any situation, is only predicted using the tokens that come before it in the factorization order.Replacing Masked Language Modeling with Permutation Language Modeling is the most important contribution from XLNet. Additionally, XLNet introduces learnable relative segment encoding on attention heads.
XLNet was not pretrained on the Next Sentence Prediction task, as it did not give a consistent improvement in performance.
Data, Hardware, Speed
The training data consists of 158 GB of text with 33B tokens.
 is trained with 512 TPU v3 chips in 5.5 days.
is trained with 512 TPU v3 chips in 5.5 days.
Other information
The contribution of XLNet to improve over BERT is distinctive and is orthogonal to most other ideas (for example, from RoBERTa) and thus, can be employed together with them, which can result in even better performance.
RoBERTa
RoBERTa: A Robustly Optimized BERT Pretraining Approach, Liu et al.
Description and Selling points
RoBERTa is one of the most (if not the most) renowned successors of BERT. It does nothing but simply optimize some hyper-parameters for BERT. These simple changes sharply enhance the model performance in all tasks as compared to BERT. Being published roughly the same time as XLNet, their performance closely matches each other, despite that the adjustments made by XLNet are much harder to implement.
Architecture
RoBERTa uses the same architecture as BERT.
Training
RoBERTa is pretrained with the MLM task (and without the NSP task).
The hyper-parameter changes made by RoBERTa are:
- Longer training time.
- Larger training data (x10, from 16G to 160GB).
- Larger batch size (from 256 to 8k).
- The removal of the NSP task.
- Bigger vocabulary size (from 30k to 50k).
- Longer sequences are used as input (but still keep the limitation of 512 tokens).
- Dynamic masking.
Data, Hardware, Speed
RoBERTa is trained on 160GB of text data using 1024 32GB V100 GPUs in 1 day.
Other information
As noted above, the improvement in RoBERTa can easily be adapted since they are mostly just changing some values in the pretraining.
DistilBERT
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, Sanh et al.
Description and Selling points
While other models aim to optimize BERT’s performance, DistilBERT has a different goal. Its target is to reduce the large size and enhance the speed of BERT ( and have 110M and 340M parameters, respectively) while still keeping as much strength as possible.
DistilBERT reduces the size of by 40%, enhances the speed by 60% while retaining 97% of its capabilities.
Architecture
DistilBERT uses a similar general architecture as BERT, but with fewer encoder blocks (6 blocks, compared to 12 blocks of and 24 blocks of ).
Also, the token-type embeddings and the pooler are removed.
The 6 encoder blocks of DistilBERT are initialized using the pretrained 12 encoder blocks of BERT (by taking 1 out of 2).
Training
DistilBERT is pretrained with the Masked Language Modeling tasks. Its objective is to optimize a triple loss:
- The language model loss, which is the same loss used in BERT.
- The distillation loss, which measures how similar the output of DistilBERT and of BERT.
- The cosine-distance loss, which measures how similar the hidden representation of DistilBERT and of BERT.
The distillation loss and cosine-distance loss help train DistilBERT in a student-teacher way, in which the student is taught to imitate the teacher.
DistilBERT also utilizes good practices from RoBERTa: a larger batch size, dynamic masking, and no NSP.
Data, Hardware, Speed
The data in use is the same as BERT (16GB of text).
DistilBERT is trained with 8 16GB V100 GPUs for 90 hours.
Other information
DistilBERT, together with BERT and RoBERTa are 3 of the most popularly used models at the time of writing this blog post.
ALBERT
ALBERT: a lite BERT for self-supervised learning of language representations, Lan et al.
Description and Selling points
ALBERT is published at roughly the same time as DistilBERT. While ALBERT also reduces the model size of BERT, it does not have to trade-off the performance. Compared to DistilBERT, which uses BERT as the teacher for its distillation process, ALBERT is trained from scratch (just like BERT).
An ALBERT configuration similar to BERT-large has 18x fewer parameters and can be trained 1.7x faster. With similar sizes, ALBERT outperforms all previous models, including BERT, RoBERTa, and XLNet.
Architecture
The contributions of ALBERT mostly come from its architectural changes. More specifically, ALBERT implements 2 parameter-reduction techniques:
- Factorized embedding parameterization: decompose the embedding matrix into 2 small matrices to separate the size of hidden layers from embedding dimension size, which enables us to increase the hidden layer size without modifying embedding dimension.
Reasoning: call E the embedding dimensions and H the hidden dimensions, it does not make sense to always have E = H (as BERT has).
ALBERT’s solution: call V the vocabulary size, we decompose the embedding matrix from size to
to  . (In particular, the embedding dimensions is reduced, and a fully-connected layer with size
. (In particular, the embedding dimensions is reduced, and a fully-connected layer with size  is added to after the embedding phase.)
is added to after the embedding phase.)
Specifically, ALBERT uses the E = 128 (while BERT uses E = 768 for and E = 1024 for ) and H = 4096 (compared to 768 in and 1024 in ). - Cross-layer parameter sharing: encoder blocks share all parameters. This does not only reduce the parameter size but also add more regularization to the model.
Also, ALBERT removes dropouts from the architecture.
Training
ALBERT also uses the MLM task with a small modification (the masked inputs are generated using n-gram masking, with the maximum n-gram span of 3).
One more important contribution of ALBERT is the introduction of the Sentence Order Prediction (SOP) to replace NSP, which was deemed too easy. SOP is more about the coherence prediction of sentences, which fits the original goal better. In contrast, NSP is more about topic prediction, which has a high correlation with MLM (and thus, doesn’t add much value to the pretraining).
Data, Hardware, Speed
ALBERT is pretrained on the union of datasets from RoBERTa and XLNet with 64 to 512 TPU V3.
Other information
While ALBERT gives a better performance with the same memory, it is not really faster than other models.
Another interesting point from ALBERT’s paper: sharing attention layers doesn’t really degrade performance while sharing fully-connected layers does.
BART
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension, Lewis et al.
Description and Selling points
BART is the next interesting pretrained model. While its performance on Natural Language Understanding tasks is comparable to that of RoBERTa, BART additionally supports tasks involving Natural Language Generation (e.g. the abstract summarization task, which requires generating new text to summarize a long input text, in contrast to the traditional summarization task that some segments of the input text are extracted to make the summary). BART’s strength on these tasks is outstanding.
Architecture
BART doesn’t follow the convention of using a similar structure to BERT which mainly consists of a stack of encoder blocks. Instead, BART uses the standard Transformer architecture (i.e. both encoder and decoder blocks are involved), with the only change being to replace ReLU with GeLU.
Training
The pretraining of BART comprises 2 steps:
- the input text is corrupted by arbitrary noise (which, as a result, may change the text length).
- the seq2seq model learns to reconstruct the original text from the corrupted text.
The noise function can be any (or any combination) of: Token Masking, Sentence Permutation, Document Rotation, Token Deletion, and Text Infilling. The best combination of noise types is dependent on the specific downstream task. However, in general, Sentence Permutation and Document Rotation alone perform poorly, while Text Infilling seems good in most cases.
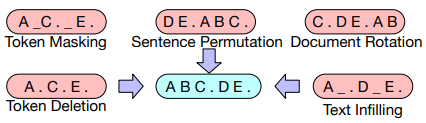
As some resources argue that dropout can hinder the performance of pretrained models, BART disables dropout for the last 10% of pretraining steps.
BART is trained on the same scale as RoBERTa (e.g. the same batch size of 8k).
Data, Hardware, Speed
The data is also the same as RoBERTa: 160GB of text.
Other information
While the advantages BART brings are inarguable, it is not really employed much in practice due to the more complex changes (including the selection of noise functions and adjustments for fine-tuning) in downstream tasks.
MobileBERT
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices, Sun et al.
Description and Selling points
MobileBERT marks a milestone in the mission of enabling performant pretrained language models to work on small mobile devices. Compared to , MobileBERT is 4.3 times smaller, 5.5 times faster but still has comparable performance.
Architecture
MobileBERT can be considered a thinner version of with some small adjustments. The authors argue that a narrow but deep neural network would possess much more strength than a wide but swallow one, given the same number of parameters. Thus, while maintaining the same number of encoder blocks as (i.e. 24), MobileBERT introduces modifications to reduce its size and shorten its runtime latency:
- A bottleneck structure, with which the inside-block hidden size is much smaller than the intra-block feature map size.
- There is a convolution layer op top of the embeddings, which compenstates for the smaller embedding dimension size.
- The so-called LayerNorm is replaced with a light-weight NoNorm operation.
- GeLUs are replaced by simple ReLUs.
- Stacks of multiple smaller feed-forward layers are to replace canonical big feed-forward layers.
On the other hand, however, unlike DistilBERT that can distill knowledge from the existing BERT model, pretraining MobileBERT requires pretraining a modified version of first, before using it as the teacher for knowledge transfer.
The architectures of the modified and of MobileBERT as compared to the original are illustrated in the figure below. Note that we call this special version of as IB-BERT (i.e. Inverted-Bottleneck BERT).

Training
At first, the IB-BERT is pretrained to convergence. Then, it is used as the teacher to transfer knowledge to the student (i.e. MobileBERT). While the embedding and the classification layers are copied directly from IB-BERT to MobileBERT, other parameters are transferred with the imitation process.
Specifically, the attention and the feature map are objectives for transfer, as shown in the figure above. The process is executed sequentially for each encoder block, one by one. Only after that, the final distillation loss of the output is then learned from the teacher to the student.
The training tasks are MLM and NSP, similar to BERT.
Data, Hardware, Speed
The pretraining process uses the same data as BERT (16GB).
IB-BERT is first pretrained on 256 TPUv3 chips.
Other information
While MobileBERT achieves incredible inference performance with a small size and short latency, its practical usage is somehow hindered by the need of pretraining a big  model.
model.
ELECTRA
ELECTRA: pre-training text encoders as discriminators rather than generators, Clark et al.
Description and Selling points
ELECTRA introduces a new pre-training objective that makes the pre-training process a lot more effective and efficient. The model now learns from all input tokens (in contrast to former models like BERT in which only 15% of the tokens have effects in model parameter learning). It matches the performance of RoBERTa and XLNet with just less than 25% computation time, outperforms them (and even ALBERT) on most GLUE and SQuAD tasks if using the same amount of computing.
Architecture
ELECTRA builds 2 models at once. The main model has an architecture that is very similar to BERT but with some small adjustments taken from XLNet. Additionally, there is a small auxiliary model to help with the learning of the main one. These 2 models share the embedding weights with each other.
Training
ELECTRA is pretrained on the Replaced Token Detection (RTD) task.
The small helper model is first trained with the MLM task. Then, it is used to fake some tokens in the input, whose output will then be fed to the main model. We also call this helper model the Generator, as it generates the input for the main model.
The main model’s objective is to discriminate tokens, answer whether each token is original or is made up by the Generator (and hence, this model is termed the Discriminator).
The process is illustrated in the below figure.
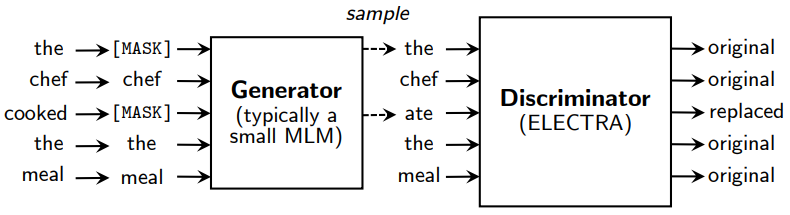
After pretraining, the Generator is thrown out. Only the Discriminator is then finetuned for downstream tasks.
Data, Hardware, Speed
ELECTRA is trained on the same dataset as XLNet (158GB of text with 33B tokens).
 gives comparable performance to
gives comparable performance to  after only 1/8 computation time (0.5 days compared to 4 days on 1 V100 GPU).
after only 1/8 computation time (0.5 days compared to 4 days on 1 V100 GPU).
Other information
While ELECTRA (more specifically, ) needs much less time to obtain comparable performance to BERT (or ), it only converges after roughly the same computation as BERT. However, after convergence, ELECTRA shows much better strength: scores 79.9 on the GLUE benchmark, which is a 4.8 points improvement over (75.1).
ConvBERT
ConvBERT: Improving BERT with Span-based Dynamic Convolution, Jiang et al.
Description and Selling points
ConvBERT can be seen as an improvement over ELECTRA. It retains the contributions from ELECTRA (i.e. the Replaced Token Detection task) and introduces an orthogonal idea to optimize the attention mechanism, which in the end results in reduced parameter size and even a much faster pretraining process. To be more specific, ConvBERT can outperform at-the-the-time-SOTA ELECTRA (by 0.7 points on the GLUE dataset) with less than 1/4 training cost.
The main insight is, while all the attention heads are global, many of them spend most of their capabilities to attend to local tokens. This fact is quite intuitive since usually, a word should share its context and meaning with nearer words around rather than words from long-distance away. Thus, it makes sense to replace some of the (complex) attention heads with something simpler that still has the ability to attend to the small local region.
Architecture
ConvBERT replaces around half of the attention heads by local convolutions. Note that this marks one of the rare attempts to modify the structure of attention-based models (other models like BERT, RoBERTa, BART just reuse the vanilla Transformer).
To achieve the most, the sheer idea of using a mixed attention convolution mechanism is inadequate. Other main contributions of the paper are listed below:
- The traditional convolution layer would not be good enough. Instead, the authors introduce the novel span-based dynamic convolution operation, which depends on the input span of tokens to generate the corresponding kernel.
- The grouped linear operator for the feed-forware layer is also beneficial. Normally, the feed-forward module allows each input value to directly affect every value of the output. However, this scheme can be redundant as many connections from the input to the output can be effectively pruned without much detrimental effect on performance. The author propose to replace this “fully” connected module with a grouped connected module, in which we split the input and output vectors into G groups, and each group of the input can only affect one group of the output values.
If we call D the number of dimensions in the input (as well as the output), then normally the number of parameters for a feed-forward module is: . With grouped linear operator, this number is reduced to
. With grouped linear operator, this number is reduced to  , where G is the number of groups, and M is the number of dimensions in an intermediate latent space.
, where G is the number of groups, and M is the number of dimensions in an intermediate latent space. - The bottleneck structure that uses a fully-connected layer to project the embedding input tokens into a lower-dimensional space (normally of half the size) before feeding to the attention modules.

Training, Data, Hardware, Speed
ConvBERT is pretrained on the Replaced Token Detection task (taken from ELECTRA), using 32GB of text data.
Based on 8 GLUE tasks, ConvBERT can give comparable or better overall performance than ELECTRA with just roughly 1/4 to 1/3 training time. Compared to BERT, ConvBERT outperforms by 4 averaged GLUE points (80.9 vs 84.9) after 1/3 training time, and by 5.5 points (80.9 vs 86.4) after 120% training time.
Other information
The small version of ConvBERT tops other training-from-scratch models while being a bit inferior to distillation models like TinyBERT and MobileBERT.
DeBERTa
Decoding-enhanced BERT with disentangled attention, He et al.
Description and Selling points
DeBERTa focuses intensively on positional encoding. Specifically, it makes improvements by introducing 2 novel techniques:
- A disentangled attention mechanism, in which word content and position are separated (in contrast to be summed up as in BERT).
- An enhanced mask decoder, in which both relative and absolute position of words are taken into account (notice that in previous work, either absolute position, e.g. BERT, or relative position, e.g. XLNet, is used).
Given the similar model size, DeBERTa outperforms former models (e.g. RoBERTa, XLNet, ALBERT, ELECTRA) in many tasks with only half of the training data, achieving SOTA performance.
Notably, the very large DeBERTa version with 1.5 parameters outperforms T5, another renowned model, which has as many as 11B parameters.
Architecture
The main structure of DeBERTa is taken from BERT with some modifications.
As stated above, the architecture requires a bit of change to accomplish the 2 new techniques: the disentangled attention mechanism and enhanced mask decoder. DeBERTa incorporates absolute word position embeddings right after all transformer blocks but before the softmax layer (as opposed to the traditional convention of summing up the embedding and the absolute positional encoding).

I = H and n = 1 then the Enhanced Mask Decoder is exactly the same as the canonical BERT decoding layer.There is also the separation of dimension size for the embedding and hidden layers, as adapted from ELECTRA.
Training
The Masked Language Modeling objected from BERT is used for pretraining DeBERTa.
In addition, the authors propose a new virtual adversarial training for fine-tuning pretrained language models, which first normalizes word embedding and then lightly perturbs the values.
Data, Hardware, Speed
DeBERTa is trained with 78GB of text data.
For the Large version, it takes 96 V100 GPUs and 20 days for training. For the Base version, 64 V100 and 10 days are needed.
Other information
The authors, afterward, try the RTD task from ELECTRA to replace the MLM. The result is very encouraging, as it performs better by a considerable margin.
BigBird
Big Bird: Transformers for Longer Sequences, Zaheer et al.
Description and Selling points
Since the canonical self-attention mechanism requires quadratic memory, it cannot handle long context with limited hardware. To address this issue, the BigBird model introduces a sparse attention mechanism that only demands linear dependency. This novel technique enables BigBird to handle longer input with the same hardware (as much as 8x) and as a result, produce better performance, especially on long-text datasets.
Architecture
BigBird reuses the architecture from BERT. Furthermore, it was initialized with the pretrained RoBERTa.
The only difference is the use of the aforementioned sparse attention to replacing the canonical attention mechanism. The sparse attention consists of 3 parts:
- a set of
gglobal tokens attending to all tokens. - all tokens attend to
wlocal neighboring tokens. - all tokens attend to a set of
rrandom tokens.
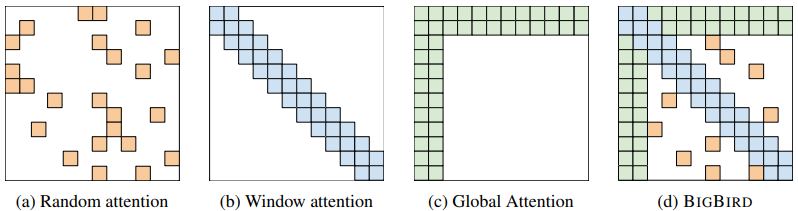
Training
The pretraining is done with the traditional MLM task.
Data, Hardware, Speed
BigBird was trained on 123GB of text data (19.2B tokens) with 8 x 8 TPU v3.
Other information
At the end of 2021, BigBird is still the SOTA for datasets with long input texts.
When to use which?
There is no best model for all cases. It depends on our current situation to select the most suitable one. Some important criteria are:
- Available hardware.
- Do we want to train from scratch or we can just finetune existing pretrained weights?
- What is/are the downstream task(s)? Are they Natural Language Understanding or Natural Language Generation?
- Does our targeted dataset contain long texts?
- What is the priority over pretraining, finetuning, and inference speed?
- Whether the model implementation is publicly avaliable?
Hardware
If the hardware we have is virtually unlimited, then we could strive for the most performant models with the largest size. A very large version of the DeBERTa can be a strong candidate for this case.
However, usually, the resources at hand are limited. Then, the Base-version of ELECTRA, DeBERTa, ConvBERT can also work well.
If we have very limited resources, then consider DistilBERT, ALBERT, TinyBERT, and MobileBERT.
Train from scratch or just fine-tune existing weights?
This is inherently related to the availability of hardware, as well as whether there are lots of public references on the model. Pretraining usually requires a lot more resources (e.g. GPUs/TPUs, time) than simply fine-tuning. Furthermore, that would not be very easy to train the model if it involves some complex operations and there are fewer references we can find to help us in implementation.
So, if the goal is to train from scratch then we should look for a model with suitable model size and is either easy-to-implement or publicly available. BERT and RoBERTa are the most popular models and have plenty of implementations on the internet. Most other models are also available on HuggingFace, however, not all of them are supported with both Pytorch and Tensorflow. So, also mind your favorite deep learning framework.
On the other hand, “just fine-tuning” requires we have access to a pretrained model (compatible with our deep learning framework) and it was trained on the same natural language. It wouldn’t make much sense if we fine-tune a model that was pretrained with English corpus on our Korean dataset. A warning is that apart from English, other languages have much fewer publicly-available pretrained models.
What is the downstream task?
Most of the above models only support (or are good options when the downstream tasks are) Natural Language Understanding problems. BART can be an exception. However, if our task is Language Generation, it is recommended to take a look at the GPT family (e.g. GPT-2).
Long text?
There are several models that are specifically designed to handle long input texts. They are XLNet, Longformer, and BigBird. BigBird is the most competent one among these.
Otherwise, if the texts are medium or short, then any other can work well.
Priority over pretraining, finetuning, and inference speed
Some models are optimized for faster pretraining while some others have much faster fine-tuning speed. ConvBERT is the best if pretraining time tops our list of priorities, ELECTRA can be considered the second choice.
Regarding fine-tuning time, normally, the smaller the model the faster it is. However, this rule of thumb is not true for models that share a lot of weights (e.g. ALBERT and its derivatives).
Public support
More recent models usually have less public support (although this can be less true for really outstanding models that gain a huge amount of attention from the community). Check it out online to see if there is any support for a specific model (notably on HuggingFace).
Summary
We summarize all the ideas in the below table.

Some other pretrained language models we have yet to include here are ERNIE, SpanBERT, UniLM, TinyBERT, Longformer, DynaBERT, T5, Megatron-LM, Reformer, and Performer.
Thank you for a great review!