
The debut of ChatGPT has made a huge splash over the entire world. Witnessing how smart ChatGPT can be, people started thinking seriously about Artificial General Intelligence (AGI) – a type of artificial intelligence that has the ability to understand, learn, and apply its knowledge to a broad range of tasks at a level equal to or beyond a human being. However, do you know precisely how far ChatGPT is from AGI? Is it already at the level of AGI? A recent study attempts to answer these questions by comparing ChatGPT’s performance to humans in a wide variety of scenarios in the field of programming education.
Scenarios
The authors compare ChatGPT-3.5 (that is, the ChatGPT version based on the older GPT-3.5 model) and ChatGPT-4 (the ChatGPT version based on the newer, stronger GPT-4 model) to humans on 6 different scenarios in programming education:
Since these 6 scenarios pretty much cover all useful applications of AI in the field of programming education, this comparison provides us with a comprehensive view of the current state of AI in this field.
ChatGPT versus Humans
The figure below nicely summarizes the results for each scenario.
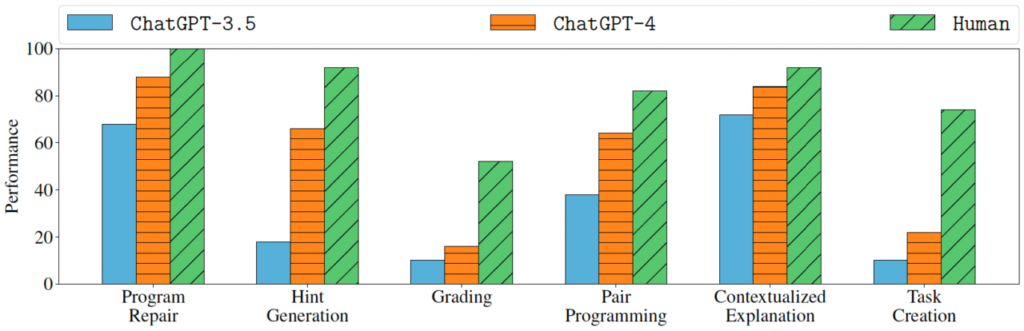
From the figure, we can see that both ChatGPT models are still inferior to real humans in all cases. For some scenarios, such as Program Repair and Contextualized Explanation, AI comes quite close to human performance. However, the gaps are significantly large for some other, harder tasks like Grading and Task Creation.
It is interesting to see that for Grading, even humans’ performance is pretty modest (about 50-55%). Note that the humans in this study are not mere laymen, but are tutors with experience in programming classes. Their moderate performance as shown in the figure indicates that different tutors may have different opinions on grading students’ programs even though they adhere to the same rubric. This is interesting. Nevertheless, the much lower performance of ChatGPT-3.5 and ChatGPT-4 cannot be explained by just differences in opinions, but the main cause should probably be their lack of knowledge and reasoning skills.
Task Creation is the second hardest scenario for both humans and AI. In this scenario, the student makes a bug in her program, and the role of humans and AI is to create a new, simpler programming exercise together with a buggy program with the same bug presented in the student’s program. The objective of this scenario is to produce new exercises for the student to practice fixing the misconception (i.e., bug) she currently has. This task is indeed non-trivial and thus, it is not surprising why both humans and AI struggled.
The paper also includes examples of outputs by ChatGPT-3.5, ChatGPT-4, and humans, which we cannot show in this blog post because of space limitations. The readers, if interested, are encouraged to check it out (the examples are at the end, in the Appendix section).
Conclusion
This work shows that while ChatGPT comes close to humans’ performance in several tasks, it still struggles with more challenging scenarios, such as Grading and Task Creation. ChatGPT, or AI in general, has not yet reached humans’ levels, at least in the field of programming education. This suggests space for improvement in future research.
Disclaimer: I am one of the authors of this work.
References:
Generative AI for Programming Education: Benchmarking ChatGPT, GPT-4, and Human Tutors, Phung et al. (2023), paper.