
In a previous blog post, we explored the performance of ChatGPT, a leading Generative AI model, in comparison to human experts for introductory programming education. As shown, ChatGPT still lags behind human tutors in all of the examined tasks such as program repair, hint generation, and grading. However, recent research has introduced a straightforward technique that significantly enhances ChatGPT’s hint generation capabilities, placing it on par with expert human tutors.
This blog post discusses an overview of this technique and the underlying intuition of its effectiveness.
Hint Generation
The technique’s primary goal is to improve ChatGPT’s performance for the task of hint generation. This section briefly introduces this task by defining the input, output, and evaluation metrics to measure the performance of any technique trying to handle the task. Before delving into more formal definitions, let us understand the task with a simple example.
Example of Hint Generation
Input:
Problem description:
Given a string S, check if it is palindrome or not.
Expected Time Complexity:  .
.
Constraints:  .
.
Buggy program:
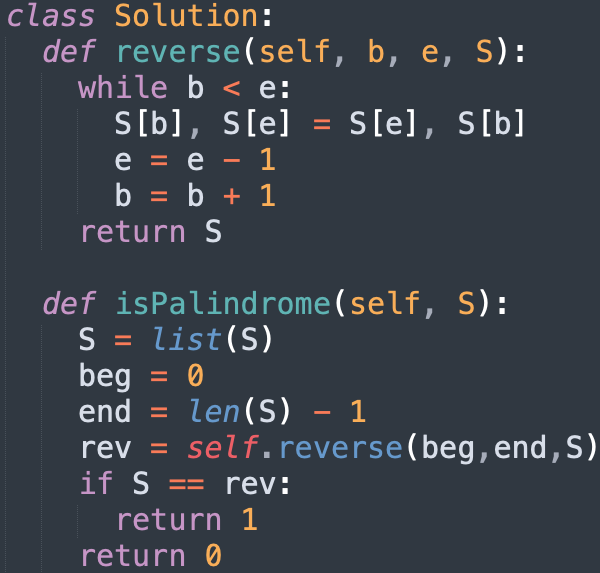
Output:
Consider the effect of Python’s pass-by-reference behavior on mutable objects like lists when you’re reversing the string.
Input:
- Problem description: The description of the programming problem a student is attempting to solve.
- Test suite: As usual, a programming problem is often accompanied by a test suite consisting of one or more test cases. A solution program (normally written by a student) is considered correct only if the program passes all of these test cases.
- Buggy program: The student’s incorrect program that fails some test cases.
Output:
- A concise hint: A short natural language feedback to be provided to the student to help them understand the bug(s) in their buggy program, fix it, and ultimately, learn from it. This hint is often one or two sentences long. A hint is good only if it correctly describes the bug(s) in the buggy program, contains useful information to help the student, doesn’t just blatantly give out the correct solution, and is easy to understand.
Evaluation Metrics:
The performance of a hint generation technique is measured using 2 key metrics – coverage and precision.
- Coverage: The percentage of buggy programs for which the technique does provide a hint. For instance, if we have 100 buggy programs that need hints and out of those 100, the technique can provide a hint for 80 of them, then the technique’s coverage is
 .
. - Precision: The percentage of good hints among those provided. Continue with the example, among the 80 hints the technique provided, if only 60 are good, then the precision is
 .
.
Among the two, precision is deemed more important, emphasizing the importance of providing good hints, even if it means sacrificing some coverage. However, this trade-off (between precision and coverage) still needs to be efficient to ensure a reasonable level of coverage.
Improving ChatGPT’s Performance
In this section, let’s look at how the proposed technique utilizes and optimizes AI models to obtain a boost in performance. The technique still uses ChatGPT (based on GPT-4, henceforth referred to as ChatGPT-4; similarly, we also denote the ChatGPT version that is based on GPT-3.5 by ChatGPT-3.5) to generate hints. However, there are two new components, among others, that are integrated: symbolic information and a validation mechanism.
Symbolic Information as Helpers for Generating Hints
The first enhancement involves adding symbolic information to ChatGPT-4’s prompt. Particularly, instead of just having the problem description and the buggy program in the prompt to ask for a hint, we can also incorporate a failing test case and a fixed program in the prompt.
Let’s go back in time a little bit. Before actually querying ChatGPT-4 for a hint, we do 2 things: (1) we run the buggy program against the test suite and take out a test case which the buggy program outputs a wrong answer, and (2) we ask ChatGPT-4 to fix the buggy program. From doing so, we obtain a failing test case and a fixed program that are to be incorporated into the prompt to ask for a hint. These two types of symbolic information equip ChatGPT-4 with more relevant data regarding the bug(s), thus making it easier to generate a good hint.
Validation of Hints by Using AI to Simulate Students
The second improvement is motivated by the observation that if the student receives a good hint, they should find it easier to fix the buggy program. Also, we can use AI models to act as students for this purpose. More concretely, the essence of this validation mechanism is as follows:
- First, we pick an AI model to act as the simulated students. Let’s say we pick ChatGPT-3.5.
- Second, we ask this “student” (ChatGPT-3.5) to generate 10 independent fixed programs for the buggy program. Note that those outputs might be different due to the stochasticity of the AI model and that some of these generated output programs might be incorrect, i.e., some might fail some test cases in the test suite. Denote the number of correct output programs as
 .
. - Next, we again ask ChatGPT-3.5 to generate 10 independent fixed programs, however, we specifically ask the AI model to fix according to the hint. Note the difference: now we emphasize the hint and instruct the “student” to follow the hint to fix the bug(s). Some of the generated output programs might be correct, let’s denote the number of correct outputs by
 .
. - Now, we compare and . If
 , that means having the hint helped the “student” to fix the buggy program more easily, and thus, the hint is validated as a good hint. Otherwise, the hint didn’t seem to help much and is then being validated as a bad hint. Only if the hint is validated as good should we provide it to the real human student. In the reversed case, no hint should be provided to the student – we intentionally reduce coverage to optimize for precision.
, that means having the hint helped the “student” to fix the buggy program more easily, and thus, the hint is validated as a good hint. Otherwise, the hint didn’t seem to help much and is then being validated as a bad hint. Only if the hint is validated as good should we provide it to the real human student. In the reversed case, no hint should be provided to the student – we intentionally reduce coverage to optimize for precision.
In a nutshell, there are 2 main ideas behind this validation stuff: One is that we can use AI models (in this case, ChatGPT-3.5) to act as students. Another is that we can look at the performance of the “students” at fixing the buggy program with and without the hint to assert the hint’s usefulness.
In the papers, the authors also introduced some other components and modifications such as having an outer loop (that if the hint is validated as bad, we restart the whole process to generate and validate a new hint, hoping to find a good hint in the new iteration) and using a more detailed explanation instead of the concise hint for validation. For brevity, we don’t include all these details in this blog post but interested readers can refer to the paper for more detail.
Results
To test the effectiveness of the proposed techniques, the authors have done experiments on 3 datasets, each consisting of buggy programs from real human students. The 3 datasets cover a wide range of introduction programming courses, from basic algorithms (such as finding Fibonacci numbers, and checking for Palindrome) to data science (writing regular expressions and working with data frames).
The table below shows the performance (i.e., precision and coverage) on the 3 datasets of the proposed technique (in green) as compared to other baselines.
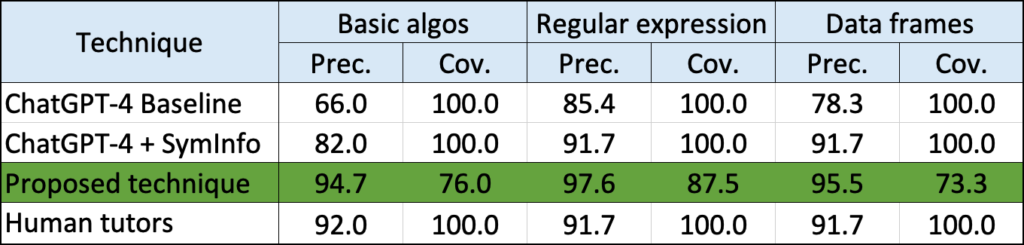
The results of the experiments demonstrated that this technique achieves precisions comparable to expert human tutors, suggesting its utility to be applied in real-world classrooms. Moreover, the trade-off in coverage to obtain such high precisions is relatively reasonable as for all datasets, the coverages remained above  .
.
For more comprehensive details, including ablations and qualitative analysis, please refer to the paper.
Conclusion
This blog post introduced a technique that enhances ChatGPT’s performance in hint generation by incorporating symbolic information and employing a validation mechanism. The results suggest that the proposed technique could be a valuable tool in educational settings, offering precision similar to expert human tutors.
Disclaimer: I am one of the authors of the two papers mentioned in this post.
References: