
This post attempts to give readers a practical example of how to clean a dataset. The data we wrangle with today is named Google Play Store Apps, which is a simply-formatted CSV-table with each row representing an application.
Dataset Name: Google Play Store Apps
Dataset Source: Kaggle
Task: Data cleaning
Language: Python
Column description
Overall, there are 13 columns:
- App: Application name.
- Category: Category the app belongs to.
- Rating: Overall user rating of the app (as when scraped).
- Reviews: Number of user reviews for the app (as when scraped).
- Size: Size of the app (as when scraped).
- Installs: Number of user downloads/installs for the app (as when scraped).
- Type: Paid or Free.
- Price: Price of the app (as when scraped).
- Content Rating: Age group the app is targeted at – Children / Mature 21+ / Adult.
- Genres: An app can belong to multiple genres (apart from its main category). For eg, a musical family game will belong to Music, Game, Family genres.
- Last Updated: Date when the app was last updated on Play Store (as when scraped).
- Current Ver: Current version of the app available on Play Store (as when scraped).
- Android Ver: Min required Android version (as when scraped).
(copied from the data source.)
Data Cleaning
Load and take an overview
# import library
from copy import deepcopy
import re
import numpy as np
import pandas as pd
# load data
df_playstore = pd.read_csv('../data/googleplaystore.csv')
In general, to have an overview of the data frame, I would print out the following information:
- data shape: the number of instances and features.
- several data rows: to have a sense of the values each data point may contain.
- data types of the columns.
- common statistics of the data frame (using .describe() method)
- Missing-value status (using .isna() method).
- The number of unique values for each column.
print('df_playstore.shape:', df_playstore.shape)
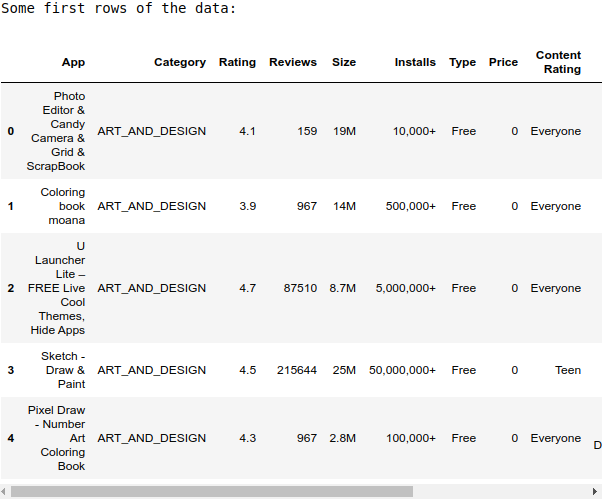
df_playstore.shape: (10841, 13)print('Some first rows of the data:')
display(df_playstore.head())
print('Column data-types:')
display(df_playstore.dtypes)
Column data-types:
App object
Category object
Rating float64
Reviews object
Size object
Installs object
Type object
Price object
Content Rating object
Genres object
Last Updated object
Current Ver object
Android Ver object
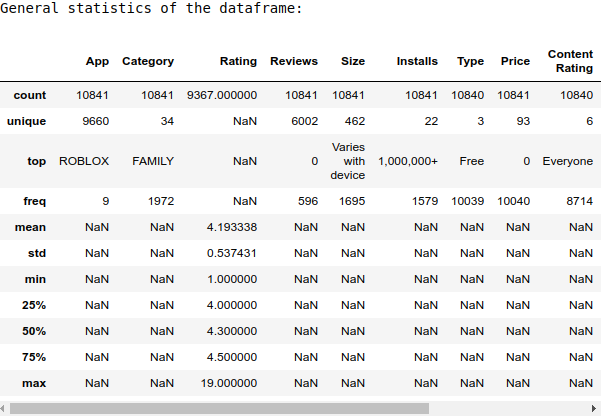
dtype: objectprint('General statistics of the dataframe:')
display(df_playstore.describe(include='all'))
print('Missing-value status:')
display(df_playstore.isna().sum())
Missing-value status:
App 0
Category 0
Rating 1474
Reviews 0
Size 0
Installs 0
Type 1
Price 0
Content Rating 1
Genres 0
Last Updated 0
Current Ver 8
Android Ver 3
dtype: int64print('Number of unique values for each column:')
df_playstore.nunique()
Number of unique values for each column:
App 9660
Category 34
Rating 40
Reviews 6002
Size 462
Installs 22
Type 3
Price 93
Content Rating 6
Genres 120
Last Updated 1378
Current Ver 2832
Android Ver 33
dtype: int64Remove duplicates
The above shows that we have 10841 rows, however, only 9660 of their App names are unique. This raises a question: Do the duplicated names refer to the same app or not?
If the Play Store restricts the app’s names that different apps must have different names, those duplicates in the dataset are duplicated data points and should be handled so that only 1 of the duplicates remains.
However, it turns out that Google does allow apps with exactly the same name, except for the names that were declared as trademarks, in which case, the names will be protected by the laws. However, we have no clue if any names from these applications have been registered as a trademark, so, to maintain data integrity, we assume that every name in this dataset is duplicatable (i.e. many apps may have the same name).
In other words, we should not delete a row just because its app name is identical to another row. Nevertheless, it is unrealistic to think that 2 different apps may be the same in every property, from the name, rating, reviews to size, etc. So, we remove the duplicates that coincide with another one in all the listed features.
df_playstore = df_playstore.drop_duplicates(keep='first')
print('df_playstore.shape:', df_playstore.shape)
df_playstore.shape: (10358, 13)Column: Last Updated
This should obviously be a Date Time column, yet, pandas recognizes it as of object type (the default data type). This implies there is an issue with this column, let’s fix it.
A simple effort to cast this column to datetime gets the following error:
pd.to_datetime(df_playstore['Last Updated'])
ParserError: day is out of range for month: 1.0.19There seem to be some rows with ill-formatted values. The below code will show those rows out.
tmp_cast = pd.to_datetime(df_playstore['Last Updated']
, errors='coerce')
df_playstore[tmp_cast.isna()]

The problem is clear: in row 10472, there is a missing for the value at the Category. To solve this, we shift all the values of this row to the right:
row_missing_value = deepcopy(df_playstore.loc[10472]) row_missing_value[1:] = row_missing_value[1:].shift(periods=1) df_playstore.loc[10472] = row_missing_value # remove the temporary variable del row_missing_value
On a side note, shifting the values of this row to right also solves the problem you may have noticed at the beginning of this work, that the maximum value of the Rating is perceived to be 19.0.
Now, how about the category of this app? Well, I do a search on the Play Store and take it that this app belongs to the LIFESTYLE group. Hoping that this app’s category hasn’t changed from 11 Feb 2018, we fill it in:
df_playstore.loc[10472, 'Category'] = 'LIFESTYLE'
Ok, so we can convert the Last Updated column into datetime without any errors.
df_playstore['Last Updated'] = (
pd.to_datetime(df_playstore['Last Updated'])
)
Column: Rating
The rating is already in the form of a float-like string, we only need to make a call to convert it.
df_playstore.Rating = df_playstore.Rating.astype(float)
Column: Reviews
Similarly, the Reviews column is also ready to be cast to the Integer type.
df_playstore['Reviews'] = df_playstore['Reviews'].astype(int)
Column: Size
Amongst all the apps in this dataset, none has its size reach 1GB. All the values we have to parse either end with ‘M’ (Megabyte), ‘k’ (kilobyte) or equal to ‘Varies with device’. The below script verifies that all of our 10358 rows fall into 1 of these 3 options.
sum((df_playstore['Size'].str.match('\d+\.?\d*M').sum(),
df_playstore['Size'].str.match('\d+\.?\d*k').sum(),
df_playstore['Size'].str.match('Varies with device').sum()
))
10358When converting these values into float, we must have them in the same unit, either MB or kB is fine. In this notebook, I choose to use the Megabyte unit, thus each app’s size that was originally in kB will be divided by 1024.
The last problem is: How to handle the ‘Varies with device‘ value. Technically, this is not so much different from NaN as we have no information about the actual size of the application. However, the take is we know that these apps have different versions available at once.
To conclude, we set the rows with ‘Varies with device‘ NaN and make a new dummy column named Variable Size to better distinguish them.
# copy the desired column to a new variable
# and work on this new variable
# to avoid unnecessary errors for the main data frame.
df_playstore_size = deepcopy(df_playstore['Size'])
# get the indexes of rows for each type of size.
index_size_M = df_playstore_size.str.endswith('M')
index_size_k = df_playstore_size.str.endswith('k')
index_size_unknown = df_playstore_size.str.match('Varies with device')
# replace the values of the copy.
df_playstore_size[index_size_M] = (
df_playstore_size[index_size_M].apply(
lambda x: float(x[:-1])
)
)
df_playstore_size[index_size_k] = (
df_playstore_size[index_size_k].apply(
lambda x : float(x[:-1]) / 1024
)
)
df_playstore_size[index_size_unknown] = np.nan
# apply the replaced value to the main data frame.
df_playstore['Size'] = df_playstore_size.astype(float)
# make a new column to emphasize the apps with
# variable size.
df_playstore['Variable Size'] = (
df_playstore['Size'].isna().astype(int)
)
# delete temporary variables.
del df_playstore_size
del index_size_M, index_size_k, index_size_unknown
Column: Installs
The number of installs is shown by buckets. Let’s see which buckets are there:
df_playstore['Installs'].value_counts()
1,000,000+ 1488
10,000,000+ 1132
100,000+ 1129
10,000+ 1033
1,000+ 891
100+ 710
5,000,000+ 683
500,000+ 517
50,000+ 474
5,000+ 469
10+ 385
100,000,000+ 369
500+ 328
50,000,000+ 272
50+ 204
5+ 82
1+ 67
500,000,000+ 61
1,000,000,000+ 49
0+ 14
0 1The smallest values are ‘0’, ‘0+’, and ‘1+’. This is quite surprising to me that both ‘0’ and ‘0+’ exist even though we need only one of them. After a bit of searching on the internet, I couldn’t find the official source of Play Store about these bucket counts. However, as stated by most other sources, ‘x+’ has the lower bound as x+1. That is, ’50+’ means 51-100, ‘100+’ means 101-500, and so on. Thus, it makes sense to deduce that ‘0’ means 0, ‘0+’ means 1, ‘1+’ means 2-5, etc. (Please correct me if I’m wrong.)
Follow the above rule, we convert this column to Integer type:
# copy the desired column to a new variable
# and work on this new variable
# to avoid unnecessary errors for the main data frame.
df_playstore_installs = deepcopy(df_playstore.Installs)
# get the indexes of the rows that are
# not ready to be converted to int.
index_install_plus = df_playstore_installs.str.endswith('+')
# convert to int
df_playstore_installs[index_install_plus] = (
df_playstore_installs[index_install_plus].apply(
lambda x : int(x[:-1].replace(',', '')) + 1
)
)
# apply the change to the main data frame
# and rename the column to make it more clear.
df_playstore['Installs'] = df_playstore_installs.astype(int)
df_playstore = df_playstore.rename(
columns={'Installs' : 'Installs at least'}
)
# delete the temporary variables.
del df_playstore_installs, index_install_plus
Column: Type
Apart from Free and Paid, this column also has 1 NaN, which is shown below:
df_playstore[df_playstore['Type'].isna()]

Notice that this is also the only row with 0 Install, which makes me feel there might be something wrong with this record.
Further investigation shows that this game seems to appear on Play Store later than the recorded time in the dataset. Wikipedia says it was first on Play Store from 2018-12-04, which is after the Last Updated value 2018-06-28.
Because of this ambiguity, I decide to remove this row from the data.
df_playstore = df_playstore.drop(9148)
This column, Type, is then replaced by ‘Is Free’ – a dummy variable.
df_playstore['Is Free'] = (
df_playstore.Type == 'Free'
).astype(int)
df_playstore = df_playstore.drop(['Type'], axis=1)
Column: Price
The price of an app seems to follow this rule: ‘0’ if it is free, else a dollar sign followed by a floating-point number. Let’s check if there are any exceptions:
print (sum(df_playstore.Price.str.match('^$\d+\.?\d*$'))
+ sum(df_playstore.Price == '0')
)
10357There is no exception. Great. We can go straight to the conversion code:
# copy the desired column to a new variable
# and work on this new variable
# to avoid unnecessary errors for the main data frame.
df_playstore_price = deepcopy(df_playstore.Price)
# get the indexes of the rows that are
# not ready to be converted to float.
index_price_dollar = (
df_playstore.Price.str.match('^$\d+\.?\d*$')
)
# do the conversion.
df_playstore_price[index_price_dollar] = (
df_playstore_price[index_price_dollar].str[1:].astype(float)
)
# apply the change to the main data frame.
df_playstore.Price = df_playstore_price
# delete temporary variables
del df_playstore_price, index_price_dollar
Note that although this Price column does cover the information of the Is Free column, I decide to keep both of them for now to emphasize the difference between free and paid apps. This use of dummy variables is elaborated in the post about when should we add a dummy variable.
Later, in case we are concerned with multicollinearity or similar issues, we would remove Is Free if necessary.
Column: Content Rating
Let’s take a look at all the content rating tags:
df_playstore['Content Rating'].unique()
array(['Everyone', 'Teen', 'Everyone 10+', 'Mature 17+',
'Adults only 18+', 'Unrated'], dtype=object)These tags seem to follow the standard of America.
We have 2 problems with this column: How should Unrated be understood and How to handle this ordinal variable.
To have a clearer view of the situation, let’s check the distribution of the values:
df_playstore['Content Rating'].value_counts()
Everyone 8383
Teen 1146
Mature 17+ 447
Everyone 10+ 376
Adults only 18+ 3
Unrated 2
Name: Content Rating, dtype: int64There are only 2 unrated apps in the dataset. As the number is so small, we have the option to remove them if we think doing so will not bias our data mining process.
For now, I decide to keep these rows to not affect the completeness of the dataset. ‘Unrated’ will be converted to NaN in the following step.
A detailed tutorial on how to treat ordinal variables is given in another post. In short, for practical purposes, ordinal variables are recommended to be converted to interval in most cases. We will stick with this for now.
# map the values of Content Rating to numbers
# and store them in another column.
df_playstore['Minimum Age'] = df_playstore['Content Rating'].map(
{'Everyone' : 0,
'Everyone 10+' : 10,
'Teen' : 13,
'Mature 17+' : 17,
'Adults only 18+' : 18,
'Unrated' : np.nan
}
)
# remove the old Content Rating,
# we already have Minimum Age as a replacement.
df_playstore = df_playstore.drop(['Content Rating'], axis=1)
Note that aside from converting tags to the corresponding ages, we also have the option to convert them to ranking, i.e. ‘Everyone’ is mapped to 0, ‘Everyone 10+’ to 1, ‘Teen’ to 2, etc.
Column: Android Ver
Look at the value counts:
df_playstore['Android Ver'].value_counts()
4.1 and up 2379
4.0.3 and up 1451
4.0 and up 1338
Varies with device 1220
4.4 and up 894
2.3 and up 643
5.0 and up 546
4.2 and up 387
2.3.3 and up 279
2.2 and up 239
3.0 and up 237
4.3 and up 235
2.1 and up 133
1.6 and up 116
6.0 and up 58
7.0 and up 42
3.2 and up 36
2.0 and up 32
5.1 and up 22
1.5 and up 20
4.4W and up 11
3.1 and up 10
2.0.1 and up 7
8.0 and up 6
7.1 and up 3
5.0 - 8.0 2
4.0.3 - 7.1.1 2
1.0 and up 2
4.1 - 7.1.1 1
5.0 - 7.1.1 1
5.0 - 6.0 1
7.0 - 7.1.1 1
2.2 - 7.1.1 1and the missing values:
df_playstore[df_playstore['Android Ver'].isna()]

we have these observations:
We would:
# function to extract the major android version from text.
# the major version starts from the beginning and
# ends before the first dot (.).
# NaN is returned if cannot extract.
def get_android_major_version(text):
try:
ver = int(text[:text.find('.')])
return ver
except:
return np.nan
df_playstore['Android Major Ver From'] = (
df_playstore['Android Ver'].apply(get_android_major_version)
)
df_playstore['Variable Android Ver'] = (
(df_playstore['Android Ver'].str
.match('^Varies with device$') == True
).astype(int)
)
# the apps whose Android ver end with 'and up'
# or equals to 'Varies with device'
# are considered still maintained
df_playstore['Is Still Maintained'] = (
df_playstore['Android Ver'].str.endswith('and up') |
df_playstore['Android Ver'].str.match(r'Varies with device')
)
# remove the no-longer-wanted column. df_playstore = df_playstore.drop(['Android Ver'], axis=1)
Note that we by removing ‘Android Ver’, we actually lose some information about the minor Android version. It depends on our purposes on mining this dataset that we decide to extract the minor version or not (in most case, the answer seems to be No).
Column: Current Ver
Some information can be extracted from this column are:
It is also worth mentioning that many values in this field do not follow the standard. I list some of those values in the table below. We will treat those as NaNs.
| newversion | acremotecontrol18 | opción de cerrar |
| Public.Heal | cli-6.5.0 | Bowser4Craigslist |
| T4.6.5-tl2.0.1 | closed | Copyright |
| KM | Cow V3.15 | MyMetro_HTML_2.0_430029 |
| a.2 | Arrow-202 | iu4 |
| H7SubTV0.1_TV0.4 | Rocksteady 1.3 | DH-Security Camera |
# prepare a function that can recognize if
# a Current Ver value indicates an updated version
# or the initial version.
# if the input value is 'Varies with device'
# that means the app has been updated.
# if the input does not follow the standard
# return NaN
# if the input follows the standard then
# extract the version and check if it is
# 1 or 1.0 or 1.0.0 etc.
app_ver_std_re = re.compile(r'(?i)(?:v|version)?:? ?(\d.*)')
first_version_re = re.compile(r'1(\.0)*$')
def recognized_has_updated(current_ver):
if current_ver == 'Varies with device':
return 1
match = re.match(app_ver_std_re, current_ver)
if match:
version = match.group(1)
if re.match(first_version_re, version):
return 0
else:
return 1
else:
return np.nan
# apply
df_playstore['Has Ever Updated'] = (
df_playstore['Current Ver'].apply(
lambda x : recognized_has_updated(str(x))
)
)
# make a column to indicate if
# the app has different versions
# for different devices.
df_playstore['Variable App Ver'] = (
df_playstore['Current Ver'].str
.match(r'^Varies with device$')
.astype(float)
)
# write a function to extract the major version
# the regex used this time is very similar
# to that of the recognized_has_updated,
# the only difference is on the capturing group.
extract_major_ver_re = re.compile(r'(?i)(?:v|version)?:? ?(\d).*')
def extract_app_major_version(current_ver):
match = re.match(extract_major_ver_re, current_ver)
if match:
major_version = match.group(1)
return major_version
return np.nan
# apply
df_playstore['Major App Ver'] = (
df_playstore['Current Ver'].apply(
lambda x : extract_app_major_version(str(x))
)
)
# Current Ver has fulfilled its role. df_playstore = df_playstore.drop(['Current Ver'], axis=1)
Column: Category and Genres
We will convert these 2 columns to numerical with one-hot encoding. It is lucky that there are no NaNs here. However, note that while an app may only belong to 1 category, there might be multiple genres associate with it.
Handling the Category is simple:
# One-hot encode Category
df_playstore = (
pd.get_dummies(
df_playstore, columns=['Category'], prefix='Cat'
)
)
It involves a bit more work for the Genres:
# cast Genres to string type
df_playstore.Genres = df_playstore.Genres.astype(str)
# split the genres of each app
df_stacked_genres = (
df_playstore.Genres.str
.split(';', expand=True).stack()
)
# apply one-hot encoding
df_genres_dummies = (
pd.get_dummies(df_stacked_genres, prefix='gen')
.groupby(level=0).sum()
)
# join the one-hot result into the main data frame
df_playstore = (df_playstore.merge(df_genres_dummies,
left_index=True,
right_index=True)
).drop(['Genres'], axis=1)
# delete temporary variables
del df_stacked_genres, df_genres_dummies
Everything is done. Here are the first 5 rows of the resulting data frame after being cleaned.
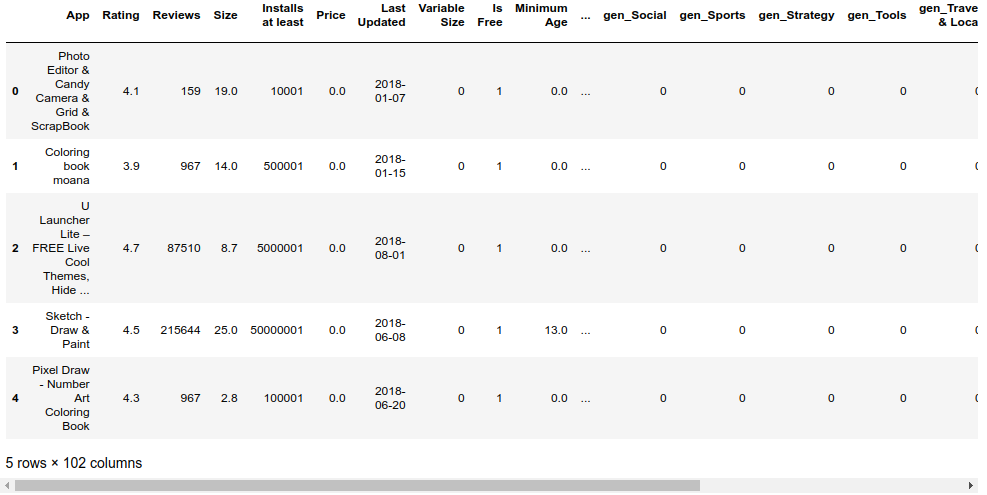
What we have done are:
The Jupyter Notebook containing full code is given here.