
How to deal with imbalanced datasets is a traditional but still everlasting problem in data mining. Most standard machine learning algorithms assume a balanced class distribution or an equal misclassification cost. As a result, their performance for predicting uneven data might get doomed by the various difficulties imbalanced classes may bring up.
In this article, we will first give the definition and state some common knowledge of the imbalanced-data problem. Then, a number of sampling methods are explained as potential solutions. We also show the experimental results collected from highly-appreciated papers proposed by experienced researchers in the field.
| Test your knowledge |
|
|
Imbalanced learning introduction
In classification, the imbalanced problem emerges when the distribution of data labels (classes) is not uniform. For example, in fraud detection, the number of positive data points is usually overwhelmed by the negative points. The ratio of different classes might be 1:2, 1:10, or even more extreme than 1:1000 in some cases. Strictly speaking, any ratio other than 1:1 is a sign of imbalance. However, we often attempt to fix the class distribution only when the difference is higher than a threshold, with the threshold value dependent on each specific dataset and user’s purpose.
Types of imbalance
With regard to where it occurs, there are Between-class and Within-class imbalances.

With regard to the nature of the problem, there are Intrinsic and Extrinsic imbalances.
With regard to the minority class’s size, there are Relative and Rare instances imbalances.
It is important to note that some studies suggested that the relative ratio of the minority class might be unharmful to the model predictions in some cases. In their paper, Weiss and Provost stated that:
…as more data becomes available, the choice of marginal class distribution becomes less and less important…
They emphasized the importance of the absolute number of minority-class data points: when the minority class is big enough, the relative imbalance will cause less damage to the classification model. However, be cautious that their metrics of performance measurement were Accuracy and AUC (Area Under the ROC Curve), and these metrics are later argued as unsuitable for imbalanced learning problems (here, for example).
More generally, in this paper, Japkowicz and Stephen concluded that the problem of imbalance data is worsened with:
…the higher the degree of class imbalance, the higher the complexity of the concept, and the smaller the overall size of the training set…
Common assumptions
Solutions by Sampling methods
Random over/under-sampling
Random oversampling means we do bootstrap sampling (random with replacement) of the minority class and add it to the dataset. Random oversampling will create multiple duplicated data points.
Advantages
Disadvantages
Random undersampling means we take only a subset of the majority points to train with all the minority samples. By doing undersampling, we reduce the relative imbalance of data by sacrificing a portion of the larger class(es).
Advantages
Disadvantages
Different studies have different views of over and undersampling performance. As an example, in this paper, Batista et al. concluded that when using C4.5 as the classifier, oversampling outperforms undersampling techniques. However, also using C4.5, Drummond and Holte found that undersampling tends to be better than oversampling.
Nevertheless, in some research, the strength of random over/under-sampling is even higher than some other more complex techniques. To be more specific, in this text, Yun-Chung stated that:
Regardless, we still feel it is significant that random undersampling often outperforms undersampling techniques. This is consistent with past studies that have shown it is very difficult to outperform random undersampling with more sophisticated undersampling techniques.
Ensemble-based sampling
EasyEnsemble
The EasyEnsemble method independently bootstraps some subsets of the majority class. Each of these subsets is supposedly equal in size to the minority class. Then, a classifier is trained on each combination of the minority data and a subset of the majority data. The final result is then the aggregation of all classifiers.
BalanceCascade
If the EasyEnsemble is somewhat similar to the bagging of weak learners, the BalanceCascade is, on the other side, seemingly related to a boosting scheme. BalanceCascade also creates a bunch of classifiers, the difference is that the input for the subsequent classifiers is dependent on the prediction of the previous ones. More specifically, if a majority-class example has already been classified correctly in the preceding phase, it is excluded from the bootstrap in the successive phases.
The authors of these 2 methods have then published a complementing paper to extensively assess their performance (using AUC, G-mean, and F-score) on various datasets. They conducted an experiment on 16 datasets using 15 different learning algorithms. The result reported is quite promising:
For problems where class-imbalance learning methods really help, both EasyEnsemble and BalanceCascade have higher AUC, F-measure, and G-mean than almost all other compared methods and the former is superior to the latter. However, since BalanceCascade removes correctly classified majority class examples in each iteration, it will be more efficient on highly imbalanced data sets.
As a side note, the classifier the authors used in each training phase of the above 2 methods is an AdaBoost.
k-NN based undersampling
Zhang and Mani proposed 4 k-NN based undersampling methods in this paper. Those are:
Through experiments explained in the same paper, the performance (in F-score) of these methods are actually not very good. They perform worse or at best comparable to random undersampling.
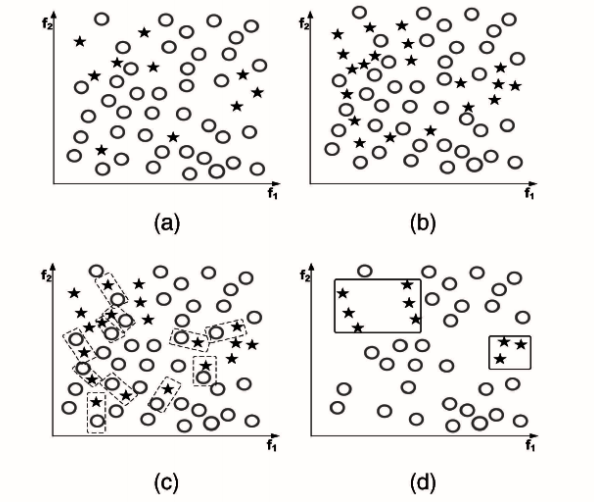
Cluster-based undersampling
A good observation is that the majority class, which is composed of many data points, might contain many subconcepts. Thus, to obtain a better undersample, we should include data points from all those subconcepts in our selection. We may cluster the majority class, then, for each cluster, a number of data points are selected for undersampling.
This idea is explained in this text by Sobhani et al. To be more specific, they use k-means to cluster the majority examples. After that, 4 methods are experimented to select the representative points from each cluster, including the NearMiss-1, NearMiss-2, and MostDistant methods proposed by Zhang and Mani that we introduced in the above section, together with using the cluster centroids.
There are 8 datasets with different imbalanced ratios (from 1:9 to 1:130) that were used for the experiment. The result, which is measured by F-score and G-mean, shows that clustering with NearMiss-1 performs slightly better than NearMiss-2, while the centroid method is the worst on average. The fact with the cluster centroids is as expected since that method does not include data points at the border, making the model unable to attain a good separation of the classes.
Condensed Nearest Neighbor undersampling (CNN)
The CNN technique also attempts to remove the “easy” data points and keep the ones that are near class borders, yet with a different idea. CNN seeks to find a subset of the original dataset by combining all minority examples with some majority examples so that every example from the original dataset can be correctly classified using the new subset with a 1-nearest neighbor classifier.
To be more clear, CNN finds its subset of choice by:
Note that the above algorithm does not guarantee to form the smallest subset that satisfies the conditions of CNN. We accept this sub-optimal algorithm as trying to find the smallest subset might be unnecessarily time-consuming.
| Test your understanding |
|
|
Synthetic Oversampling (SMOTE)
SMOTE, which was proposed here by Chawla et al., stands for Synthetic Minority Oversampling TEchnique. Unlike random oversampling and the above-mentioned undersampling techniques whose resulting data consists of only the original data points, SMOTE tries to create new, synthetic data based on the initial dataset.
First, SMOTE finds the k nearest neighbors for each of the minority-class data points. Second, for each minor point, it randomly selects one of these k neighbors and randomly generates one point in between the current minority-class example and that neighbor. The second step is repeated until the size of the minority class satisfies our needs.
The SMOTE method is one of the most popular sampling techniques for imbalanced datasets, thanks to its good and stable performance over most types of datasets.
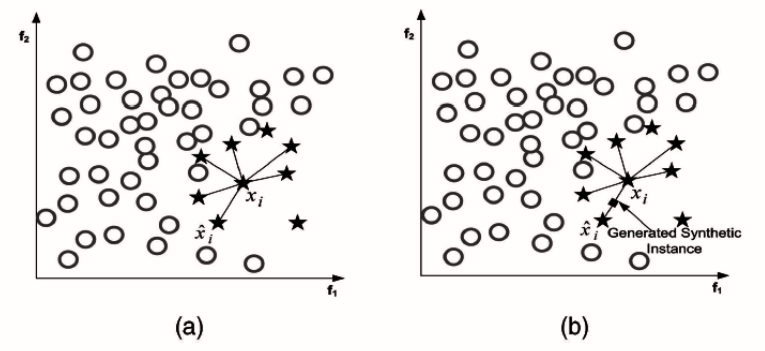
 , k nearest neighbors are taken into account (in this example, we choose k = 6). b) One of the k nearest neighbors is selected at random, then, the new data point is generated randomly between and the selected neighbor. Figure from this paper.
, k nearest neighbors are taken into account (in this example, we choose k = 6). b) One of the k nearest neighbors is selected at random, then, the new data point is generated randomly between and the selected neighbor. Figure from this paper.Advantages
Disadvantages
Borderline-SMOTE
This method is similar to the original SMOTE in terms of trying to generate synthetic minority-class data points from the original dataset. However, for Borderline-SMOTE, only the minor points that are at the border are used as seeds for generating.
To determine whether a minor point is at the border, we consider its m nearest neighbors. If over those m nearest neighbors, the number of major points is at least as large as  and smaller than m, this point is considered a borderline minority-class point. Note that if all m nearest neighbors of a minor point belong to the major class, that minor point is considered noise and thus is not chosen.
and smaller than m, this point is considered a borderline minority-class point. Note that if all m nearest neighbors of a minor point belong to the major class, that minor point is considered noise and thus is not chosen.
This method is proposed as a variation of SMOTE that tries to fix its over-generalization problem.
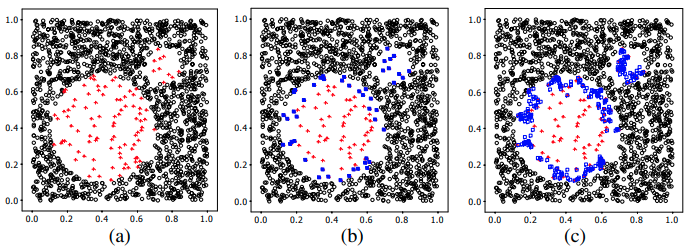
The authors also did some experiments to compare Borderline-SMOTE with the existing methods (using F-value and True Positive Rate). Over the 4 datasets that were tested on, Borderline-SMOTE and SMOTE show comparable results for 3 datasets, but for the last one, Borderline-SMOTE beats all others for a large margin. It is also worth it to note that the original data without any kind of sampling gives a much worse outcome than with any of the tested methods.
ADA-SYN
Being similar to Borderline-SMOTE, ADA-SYN (adaptive synthetic oversampling) also comes in to address the over-generalization problem of the original SMOTE. However, instead of using a hard cut-off threshold at , ADA-SYN generates more synthetic data points from the minority examples that are surrounded by more majority examples.
In particular, first, a number of m nearest neighbors are identified for each minority point. Then, each minority point is assigned with a ratio:

with  is the number of majority points in the m nearest neighbors of , Z is a normalization constant so that
is the number of majority points in the m nearest neighbors of , Z is a normalization constant so that  . Finally, the number of synthetic points generated from the seed is linearly proportional to
. Finally, the number of synthetic points generated from the seed is linearly proportional to  .
.
ADA-SYN can be viewed as a generalization of Borderline-SMOTE with regard to its flexibility. It places more emphasis on the points near the borders but doesn’t abandon the points that are a bit farther away. Furthermore, in the last step, instead of using a linear proportion, we can flexibly change it to a log, a quadratic, or an exponential proportion as needed.
In their experiment with 5 datasets, the authors compare ADA-SYN with the original SMOTE and the original data for a decision tree classifier. It is shown that the G-mean value is highest for ADA-SYN with all datasets, while for F-measure, ADA-SYN is the winner 3 over 5 times. It is also interesting that, as in their experiment, applying a decision tree on the original, imbalanced datasets always results in the best Precision.
Sampling by cleaning
There are 2 crucial reasons behind cleaning:
Tomek link
Suppose we have two different data points and  , and are of different classes. Let’s call d(, ) the distance between and . If there is no third point
, and are of different classes. Let’s call d(, ) the distance between and . If there is no third point  such that d(, ) < d(, ) or d(, ) < d(, ), and are said to form a Tomek link. In other words, 2 points form a Tomek link if they are of different classes and each of them is the nearest neighbor of the other.
such that d(, ) < d(, ) or d(, ) < d(, ), and are said to form a Tomek link. In other words, 2 points form a Tomek link if they are of different classes and each of them is the nearest neighbor of the other.
For a pair of points that form a Tomek link, either one of them is noise or both of them are near a border of the two classes. Thus, we may want to remove all those pairs to make the dataset more concrete and separable.
The trick of Tomek link cleaning is often not performed alone but in companion with a sampling technique. For example, one may remove all Tomek links after oversampling with SMOTE.
Edited Nearest Neighbor rule (ENN)
The ENN rule seeks to address the same problem as the Tomek link rule, but with a slightly different scheme: A data point is removed if and only if it is different from at least half of its k nearest neighbors, with k is a pre-defined hyperparameter.
Batista et al. did an experiment using Tomek link and ENN together with SMOTE on 13 datasets and showed the result in this paper. The imbalance ratios of these datasets vary from 1:2 to 1:38. Quoted from the paper:
… Smote + Tomek and Smote + ENN are generally ranked among the best for data sets with a small number of positive examples.
Cluster-balancing oversampling (CBO)
The cluster-balancing oversampling technique not only strikes to work on the problem of between-class imbalance but also the within-class imbalance issue. In general, it tries to make the data size of each subconcept more uniform.
The actual behaviors that CBO aims for are:
To achieve the above, we follow these steps:
- Cluster the majority and minority classes separately. They will then have
 and
and  clusters, respectively. Each of these clusters might have its own number of data points.
clusters, respectively. Each of these clusters might have its own number of data points. - Let’s call
 as the size of the largest majority-class cluster. For all other clusters of the majority class, oversample them independently so that each has size . After this step, we have a total of
as the size of the largest majority-class cluster. For all other clusters of the majority class, oversample them independently so that each has size . After this step, we have a total of  majority-class data points.
majority-class data points. - Finally, we oversample each of the minority-class cluster so that each of them has size
 .
.
Note that, unlike the above-mentioned techniques that only oversample the minority class, CBO does oversample both minority and majority classes. The clustering step might be performed using k-means or any other clustering algorithms. Similarly, the oversampling step might also be conducted with random oversampling (as in this paper), SMOTE, or other techniques.

Oversampling with boosting
SMOTEBoost
SMOTEBoost was introduced in this paper by Chawla et al. This method integrates SMOTE into each iteration of boosting. That is: before any subsequent weak learner is created, the SMOTE is applied to generate some new synthetic minority examples.
This brings several advantages:
In the same paper, the authors compare the performance of SMOTEBoost with AdaCost, first SMOTE then Boost, and SMOTE only. There are 4 datasets that were used in the experiment. The result is promising: SMOTEBoost, in companion with RIPPER classifier, edges the other methods (on F-value) on 3 over 4 datasets.
DataBoost-IM
Hongyu Guo and Viktor proposed the DataBoost-IM as an adaptation for imbalanced data of their earlier DataBoost, which was aimed to handle balanced datasets. With this implementation, the subsequent classifiers do not only focus on misclassified examples but also give more attention to the minority class.
DataBoost-IM generates synthetic data for both minority and majority classes when maintaining a boosting scheme. In fact, as minority data is usually much harder to learn than the majority data, we expect to see more minority data points on the top of the misclassified ranking, which results in more synthetic minority points generated than majority points.
Let’s call the original training data S, we have  and
and  are subsets of S that correspond to the minority and majority classes, respectively. At each iteration of boosting, we select m hardest-to-predict data points, call this set E.
are subsets of S that correspond to the minority and majority classes, respectively. At each iteration of boosting, we select m hardest-to-predict data points, call this set E.  and
and  are the subsets of E containing examples from minority and majority classes, respectively. We expect || > || since minority points are generally harder to predict. The number of synthetic data points to be generated for the majority class is
are the subsets of E containing examples from minority and majority classes, respectively. We expect || > || since minority points are generally harder to predict. The number of synthetic data points to be generated for the majority class is

The number of synthetic data points to be generated for the minority class is

An experiment with 8 datasets shows that even though the G-mean measurement does not go well with DataBoost-IM all the time, its performance measured by F-score is usually better than other methods, including the aforementioned SMOTEBoost.
Over/Under Sampling with Jittering (JOUS-Boost)
While Random oversampling is easy and fast, it creates duplicates of data (i.e. ties). As having ties potentially makes the classifier more prone to over-fitting, synthetic oversampling techniques like SMOTE are then introduced to resolve this problem. However, these synthetic techniques also have their own drawbacks, they are more complicated and expensive in time and space.
The JOUS-Boost is claimed to be able to address both the weaknesses of the two techniques while inheriting their advantages.
It turns out that, to break the ties, we do not have to move the generated samples to the direction of one of the nearest neighbors, as SMOTE does. Instead, we can move it a little bit to any random direction. This is what is meant by “Jittering”: a little i.i.d noise is added to the data points generated by random oversampling.
Conclusion and further read
The problem of data imbalance might result in a big and bad effect on our predictions and analysis. To deal with imbalanced data, using resampling techniques is a traditional but effective solution.
In this article, we introduce various types of resampling techniques, from simple random over/under-sampling, ensemble-based, k-NN based, cluster-based, SMOTE together with its variants, to combinations of resampling with cleaning, boosting, and jittering.
The reason why there are many resampling techniques of interest is that, according to many studies, none of the techniques is the best for all (or almost all) situations.
…the best resampling technique to use is often dataset dependent…
Yun-Chung Liu, in this paper.
However, overall, we may take it that using ensemble, or to be more specific, boosting, is more beneficial than a single classifier in most cases. Additionally, for each round of boosting, it is recommended to vary some parameters, e.g. the training set and the imbalance ratio.
Other than Resampling, there is another method that is also often used, which is called Cost-Sensitive Learning (the AdaCost we mentioned in the above sections is an example). Furthermore, this alternative method has become increasingly more popular with flying colors:
…various empirical studies have shown that in some application domains, including certain specific imbalanced learning domains, cost-sensitive learning is superior to sampling methods.
Haibo He and Garcia, in this text.
However, it is not so clear who the winner is in dealing with imbalance, sampling, or cost-sensitive techniques. Weiss et al. have conducted an extensive experiment targeting this question and here is their conclusion:
Based on the results from all of the data sets, there is no definitive winner between cost-sensitive learning, oversampling and undersampling.
In general, sampling has its own indisputable advantages:
An introduction and discussion about Cost-Sensitive Learning methods for imbalanced datasets will be presented in a future post.
| Test your understanding |
|
|
References:
- Learning from Imbalanced Data, Haibo He and Garcia, link
- Cost-sensitive boosting for classification of imbalanced data, Y Sun et al., link
- The class imbalance problem: A systematic study, Japkowicz and Stephen, link
- Learning When Training Data are Costly: The Effect of Class Distribution on Tree Induction, Weiss and Provost, link
- The Effect of Oversampling and Undersampling on Classifying Imbalanced Text Datasets, Yun-Chung Liu, link
- Cost-Sensitive Learning vs. Sampling: Which is Best for Handling Unbalanced Classes with Unequal Error Costs? , Weiss et al., link
- The Relationship Between Precision-Recall and ROC Curves, David and Goadrich, link
- Exploratory Undersampling for Class-Imbalance Learning, Xu-Ying Liu et al., link
- KNN Approach to Unbalanced DataDistributions: A Case Study Involving Information Extraction, Zhang and Mani, link
- Learning from Imbalanced Data Using Ensemble Methods and Cluster-based Undersampling, Sobhani et al., link
- SMOTE: Synthetic Minority Over-Sampling Technique, Chawla et al., link
- Borderline-SMOTE: A NewOver-Sampling Method in Imbalanced Data Sets Learning, Hui Han et al., link
- ADASYN: AdaptiveSynthetic Sampling Approach for Imbalanced Learning, H. He et al., link
- A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data, Gustavo et al., link
- Class imbalances versus small disjuncts, Taeho Jo and Japkowicz, link
- SMOTEBoost: Improving Prediction of the Minority Class inBoosting, Chawla et al., link
- Learning from Imbalanced Data Sets with Boosting and Data Generation: The DataBoost-IM Approach, Hongyu Guo and Viktor, link
- Boosted Classification Trees and Class Probability/Quantile Estimation, Mease et al., link
- Cost-Sensitive Learning vs. Sampling: Which is Best for Handling Unbalanced Classes with Unequal Error Costs? , Weiss et al., link