
This blog post summarizes the unique characteristics of the Python programming language together with some tips & tricks.
Underscores in naming
_<name>: a leading underscore conventionally suggests that this variable is only for internal uses, e.g. inside a class definition, inside a Python file. Thus, variables with a prepended underscore will be excluded from importing, i.e. from <file-name> import *
<name>_: a trailing underscore is usually used if our intended variable name coincides with a Python keyword. For example, we shouldn’t name a variable class as this term is preserved by Python, instead, we may name it class_.
__<name>: 2 leading underscores signal the variable to be private, i.e. subclasses will not inherit this variable from the parent class. To ensure that to be the case, an attribute with 2 leading underscores in its name (i.e. __<name>) is actually saved as _<class-name>__<name>.
__<name>__: names with 2 leading and 2 trailing scores are usually reserved for built-in attributes and methods, e.g. __eq__, __len__ (these are also called dunder methods).
isinstance
isinstance(<variable>, <class>) returns True if and only if the variable is an object of the class. However, be warned that some subtle problems can happen. For example, isinstance(5, float) returns False, which is undesirable in many cases. This is because Python recognize 5 as an int, not a float, which contradicts our intuition that integers are contained in float.
To prevent this and similar issues, it is a good practice to always pass a base class to the <class> argument. For example, in the above case, we can change the call to isinstance(5, numbers.Number).
To check if a variable is dictionary-like, it is recommended to use isinstance(<variable>, abc.Mapping), where abc (short for abstract base class) is imported from collections.
Hash
An object is hashable if its hash value never changes during its lifetime and can be compared to other objects. All immutable objects are hashable (except when it contains unhashable objects). No mutable containers are. By default, user-defined types are hashable by their id.
Programmatically, to make a type hashable, we define its __hash__ method (which returns the same value during the variable’s lifetime) and its __eq__ method.
Decorators
Decorators help with wrapping boiler-plate code around functions and classes. In Python, 4 of the most popular decorators are @classmethod, @staticmethod, @property, and @dataclass.
@classmethod: while a normal method takes the current object (i.e. self) as the first argument, a class method instead takes the class. The most common use-case of a class method is to be an alternative constructor.
class Vector:
def __init__(self, x: float, y: float):
self._x = x
self._y = y
...
@classmethod
def from_string(cls, s: str):
x, y = s.split()
return Vector(float(x), float(y))
@staticmethod: a static method does not require any obligatory first-argument. It works independently from the class and object. We may use a static method instead of a regular function (i.e. moving the method out of the class definition) to indicate that this method is somehow bound with this class. Another use-case is when we want to assemble all utility functions into a class for easier management.
class Util:
@staticmethod
def load_and_parse_file(file_path: str):
with open(file_path, 'r') as f:
content = f.read()
lines = content.split('\n')
return lines
@staticmethod
def save_files(content: str, file_path: str):
with open(file_path, 'w') as f:
f.write(content)
@property: enables a method to be used as a property. This decorator is often used on a private attribute to make its value queriable but not modifiable. If modifiability of attribute values is desired, we can add a setter method, which allows for checks before applying the changes.
class Vector:
def __init__(self, x: float, y: float):
self._x = x
self._y = y
@property
def x(self):
return self._x
@x.setter
def x(self, value):
if isinstance(value, float):
self._x = value
else:
raise ValueError('Cannot set x to a non-float.')
@dataclass: Unlike the above, this decorator is used for classes but not methods. If we mark a class as a data class (by using this decorator), among others, we can save quite a handful of boilerplate code for initialization (in __init__), making it hashable (with __eq__ and __hash__), and representation (with __repr__).
from dataclasses import dataclass
from typing import Tuple
@dataclass(frozen=True) # set frozen=True to make it hashable
class Invoice:
customer_id: int
list_of_purchases: Tuple[float]
def calculate_total_purchase(self):
return sum(self.list_of_purchases)
# this works because @dataclass handles the __init__
invoice = Invoice(123, (32.2, 11.99, 6.8))
# this works because @dataclass handle the __repr__
print(invoice) # output: Invoice(customer_id=123, list_of_purchases=(32.2, 11.99, 6.8))
# this works because a dataclass is still a class, it can have user-defined methods
print(invoice.calculate_total_purchase())
# this works because dataclass handles __eq__ and __hash__ as we set frozen=True
print(hash(invoice))
To define our own decorators, remember:
@d def f():... # is equivalent to f = d(f) @d1 @d2 def f():... # is equivalent to f = d1(d2(f)) @d(params) def f():... # is equivalent to f = d(params)(f) # here d is a decorator factory that returns a decorator
Mutable and Immutable
A variable type is either mutable or immutable. A type is mutable if its objects’ internal state (i.e. their content) can be changed keeping the same id address. Conversely, for immutable variable types, its objects’ content cannot be changed without being assigned a new id.
Common mutable types are:
- List,
- Set,
- Dictionary,
- User-defined classes (are mutable by default, but can be adjusted to make them immutable).
Common immutable types are:
- Boolean and number types (e.g. Int, Float),
- String,
- Tuple.
Note how mutable types often have a method to add values into their internal state (e.g. append() for List, add() for Set), while immutable variables do not.
Passing by value or reference?
In Python, we don’t directly specify in the function definition which arguments should be passed by value and which should be passed by reference. In other words, all arguments are passed in the same way, and we call it passing by assignment.
If the passed variable is mutable then when we change its value (e.g. append, add, but not re-assign) from inside the function, its value outside the function also changes (similar to being passed by reference). On the other hand, if the variable is immutable then changes inside the function will not be reflected to the outside (similar to passed by value).
An advantage of passing by assignment is in either case, mutable or immutable, just passing the variable to the function does not incur the cost of copying its value.
List, Tuple, Array, and Generator
List and Tuple are quite similar in that they are containers containing elements in a specific order. Also, their elements can be of different types. The main difference between them is that while List is mutable, Tuple is immutable. Thus, we often use Tuples to indicate that the variable is not supposed to be changed, and use Lists otherwise.
The Array is different from List and Tuple in the sense that it can only contain values of the same type. Thus, with the cost of being less flexible, Array requires less memory space to store. In practice, it is rarely the case to use Array, we usually prefer List. If someone says she uses Python Array, it is very likely she actually means Numpy Array, a much more performant data type for math operations.
Generators are the best for memory saving. They don’t actually store values, but rather create one value at a time to fetch to our computation loop. Thus, generators basically require almost zero memory space. The downsides are: there is no slicing possible, we have to access the value one by one from first to last; and the sequence of values needs to be relatively simple so that it can be generated efficiently within a function.
Identity, equality, aliases, ==, and is
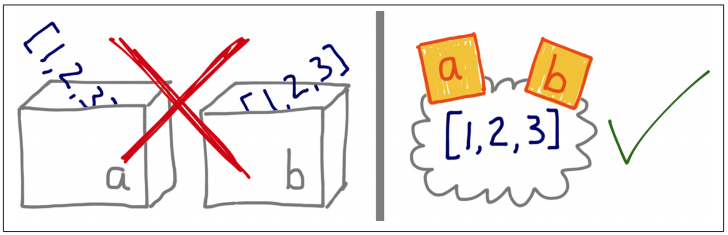
Each object (or variable) has a unique identifier (id, for short) that never changes. 2 objects are equal if their values are the same. 2 objects are the same if their id are the same.
2 aliases can be understood as 2 variables (or 2 sticky notes) that are stuck to the same object.
A shallow copy creates an alias, while a deep copy creates a new object that has the same value as the original one.
== is meant to compare values, while is is to compare identities. When we call ==__eq__ of the corresponding type.
For user-defined types, Python doesn’t know what values an object of this type may contain, so it cannot implement the == as it is supposed to do. Thus, Python takes a conservative choice to fall back to using is when we call ==, i.e. by default, user-defined types‘ == compare identities. Hence, it is often recommended to overload the __eq__ method of user-defined types to compare values.
Shallow and Deep copy
Copies are shallow by default. However, shallow and deep copies are the same to our eyes if every object copied is immutable.
Shallow copies may make things complicated. To avoid these problems, we can use deep copies:
import copy l1 = [1, [2, 3], (4, 5)] l2 = l1 # shallow copy l3 = list(l1) # shallow copy l4 = copy.deepcopy(l1) # deep copy l1[1].append(40) print(l1) # output: [1, [2, 3, 40], (4, 5)] print(l2) # output: [1, [2, 3, 40], (4, 5)] print(l3) # output: [1, [2, 3, 40], (4, 5)] print(l4) # output: [1, [2, 3], (4, 5)]
Also, never use a mutable object as default for any function. Reason: the default object for any parameter is evaluated when the function is defined, this object is assigned to every time it is needed to be. See below code.
class HauntedBus:
def __init__(self, passengers=[]):
self.passengers = passengers
def pick(self, name):
self.passengers.append(name)
def drop(self, name):
self.passengers.remove(name)
bus1 = HauntedBus()
bus1.pick("Tung")
bus2 = HauntedBus()
print(bus2.passengers) # output: ['Tung']
Mutable object as a parameter: unless a method is explicitly intended to mutate an object it receives as an argument, we should think twice before aliasing the argument object by simply assigning it to an attribute of our class.
class TwilightBus:
def __init__(self, passengers=None):
if passengers is None:
self.passengers = []
else:
self.passengers = passengers
def pick(self, name):
self.passengers.append(name)
def drop(self, name):
self.passengers.remove(name)
basketball_team = ["A", "B", "C", "D"]
bus = TwilightBus(basketball_team)
bus.drop("C")
print(basketball_team) # output: ['A', 'B', 'D']
The collections module
The collections module contains a few container data types that are very useful in practice. Let us take a quick look at the most popular ones:
deque (short for double-ended queue) is a queue that can push and pop from both ends. deque is thread-safe, so it is also suitable for multi-thread programming.
Counter: a subclass of dictionary that is specialized for counting occurrences of values.
defaultdict: a dictionary with a user-defined default value.
Hash table, Set, and Dict
Hash table (rather than Binary Search Tree) is the data structure behind Dict and Set. Because of this, dicts and sets have a high memory overhead but very fast querying.
Set elements and Dict keys must be hashable. However, sets and dicts themselves are not hashable. Frozenset is.
Supported set operations are: & (intersection), | (union), - (difference), ^ (symmetric difference, or XOR).
A set s1 is smaller than another set s2 if s1 is a proper subset of s2. Programmatically, s1 < s2 and s2 > s1 return True if and only if s1 is a proper subset of s2.
Bytes and texts
In general, we should never open text files in binary mode unless we need to analyze the file contents to detect the encoding.
In Python, byte type is immutable while bytearray type is mutable (as array is mutable).
Text normalization: different code points may represent the same character. Furthermore, a length-2 code point may represent the same character as another length-1 code. Thus, we need normalization to help make visually similar strings identical sequences of bytes. NFC is the most popular normalization standard.
from unicodedata import normalize
s1 = "café" # composed "e" with acute accent
s2 = "cafe\u0301" # decomposed "e" and acute accent
print(s1, s2) # output: café café
print(len(s1), len(s2)) # output: (4, 5)
print(s1 == s2) # output: False
print(normalize("NFC", s1) == normalize("NFC", s2)) # output: True
Sort
The built-in sort function in Python implements a hybrid stable algorithm called Timsort, which is a combination of Insertion sort and Merge sort. It takes advantage of the observation that many real-life sequences have runs of already ordered elements. Insertion sort is used to form consecutive runs of ordered elements so that each run satisfies at least a predefined minimum size. Then, Merge sort is applied on the runs. This algorithm requires a linear space complexity and achieves  worst-case time complexity. More details can be found on Wikipedia.
worst-case time complexity. More details can be found on Wikipedia.
Function
Function as a first-class object: in Python, functions can be thought of as a special type of variable. Thus, a function can be:
- assigned to by a variable.
- passed as an argument to a function.
- returned as the result of a function.
With this property, functions can easily be used for Strategy and Command design patterns, the patterns that normally need classes with a single method (run, execute, doIt) and no attributes.
lambda functions are not very readable and are limited to a pure expression (i.e. cannot contain while, try, for, etc.). Lambda functions are only useful when being passed as an argument to a function.
partial function: we can freeze arguments of a function with functools.partial.
import unicodedata
import functools
nfc = functools.partial(unicodedata.normalize, "NFC")
s = "cafe\u0301"
print(nfc(s)) # output: café
print(nfc(s) == unicodedata.normalize("NFC", s)) # output: True
Callable
User-defined classes may also be callable if we implement the __call__ method.
class Count:
def __init__(self):
self.num = 0
def __call__(self):
self.num += 1
return self.num
count = Count()
print(count()) # output: 1
print(count()) # output: 2
print(count()) # output: 3
We can check whether an object is callable using the callable function.
print(callable(count)) # output: True
Positional and keyword arguments
Take a look at the function below:
def func(a, *b, c, **kwargs):
print(a, b, c, kwargs)
acan be passed as either a positional or a keyword parameter.cis a keyword-only parameter because all positional parameters after the first one are taken byb.**kwargstakes all keyword arguments that are not specified in the function definition (i.e. every keyword parameters other thanaandc).
func("tung", 10, b=1, c="123") # output: tung (10,) 123 {'b': 1}
operator module
The operator module is very useful for functional programming. Some of the most popular operators it supports are itemgetter, attrgetter, and methodcaller.
from operator import itemgetter
arr = [('b', 1), ('a', 1), ('a', 0)]
# below, itemgetter(1) means the same as lambda x: x[1]
print(sorted(arr, key=itemgetter(1))) # output: [('a', 0), ('b', 1), ('a', 1)]
# below, itemgetter(1, 0) means the same as lambda x: (x[1], x[0])
print(sorted(arr, key=itemgetter(1, 0))) # output: [('a', 0), ('a', 1), ('b', 1)]
Scope
In Python, variables can have one of the three different scopes: globalnonlocal, and local. Say we are inside a function, the scope of any variable can be defined by the following rules:
- If the variable is explicitly stated as
globalornonlocal, then it is. - Else if somewhere in the function the variable is assigned to a value, then that variable is recognized as
local. - Else the variable is
global.
b = 5
def f1():
global b
print(b)
b = 100
f1() # output: 5
print(b) # output: 100
def f2():
print(b)
b = 200
f2() # output: UnboundLocalError: local variable 'b' referenced before assignment
Closure
A closure is a record storing a function together with an environment.
Wikipedia
Let’s take a look at the below code for example.
def make_averager():
total = 0
count = 0
def averager(v):
nonlocal total, count
total += v
count += 1
return total / count
return averager
avg = make_averager()
print(avg(10)) # output: 10
print(avg(20)) # output: 15
print(avg(30)) # output: 20
Here, averager is a function to compute the average of all passed values so far. make_averager is a function factory. avg is a closure because it stores a function (averager) together with the environment (total and count).
del and Garbage Collection
del does not delete objects, it only deletes the variable (i.e. the sticky note) and the reference from the variable to the object. Basically, an object is only deleted when there is no reference to it.
Note that weak references do not count. Weak references are, for example, for caching (we don’t want the object to be kept just because it is cached).
Pythonic object
Here, we introduce some (dunder) methods that user-defined types need to implement to fulfill some purposes:
__str__: returns a string representation that the user wants to see.__repr__: return a string representation that the developer wants to see. Usually, this string shows how to construct the current object by calling its constructor.__iter__: to make the objects unpackable, iterable.__eq__: to make==viable, also help making object hashable (together with__hash__).__getitem__: to allows list-like or dict-like access (__setitem__for modifications).
class Vector2d:
def __init__(self, x, y):
self.__vector = (float(x), float(y))
@classmethod
def from_string(cls, s):
x, y = (float(item) for item in s.split())
return cls(x, y)
@property
def x(self):
return self.__vector[0]
@property
def y(self):
return self.__vector[1]
def __iter__(self):
return (v for v in self.__vector)
def __eq__(self, other):
return tuple(self) == tuple(other)
def __str__(self):
return str(tuple(self))
def __repr__(self):
class_name = type(self).__name__
return "{}({!r}, {!r})".format(class_name, *self)
def __hash__(self):
return hash(self.x) ^ hash(self.y) # this is a simple way of hashing.
def __getitem__(self, i):
return self.__vector[i]
# below calls the __init__ method
v = Vector2d(3, 4)
# below calls the __iter__ method
x, y = v
print(x, y) # output: 3.0 4.0
# below calls the __eq__ method
print(v == (3, 4)) # output: True
# below calls the __str__ method
print(v) # output: (3.0, 4.0)
# below calls the __repr__ method
print(repr(v)) # output: Vector2d(3.0, 4.0)
# below calls the __hash__ method
print(hash(v)) # output: 7
# below calls the __getitem__ method
print(v[1]) # output: 4.0
# below calls the from_string method
v2 = Vector2d.from_string("4.2 2.5")
print(v2) # output: (4.2, 2.5)
Protocols and Duck Typing
If it quarks and behaves like a duck in all aspects that we need a duck to behave, then we consider it a duck without knowing if it is really a duck or not. Duck Typing in Python upholds this idea, accepting an object if that object can be used for a particular purpose without having to check its type.
A protocol is an informal interface, defined only in documentation and not in code. For example, the protocol of a sequence is to have __len__ and __getitem__ implemented.
With Duck-Typing, to make sure if the variable really “quarks like a duck”, we may make a copy of it using the copy constructor of the intended type. For example, suppose we want the input to “quark” like a list, do: input = list(input). This will throw an error if the input cannot “quark” like a list.
Note that Duck Typing goes against type-check and makes the code base more difficult to track. Thus, in general, Duck Typing is not encouraged, especially for medium and large-size projects.
Monkey-patching
Monkey-patching refers to the ability to change a class or module at runtime without modifying its source code. Python is flexible enough to support monkey-patching, as illustrated below:
class C:
def foo():
print("This is before monkey-patched.")
C.foo() # output: This is before monkey-patched.
def new_foo():
print("This is after monkey-patched.")
# monkey-patching
C.foo = new_foo
C.foo() # output: This is after monkey-patched.
Note that the mutability of a class can be changed during run-time if we monkey-patch its __setitem__ method.
Dynamic attribute access
Generally, when an object’s attribute is called, Python first finds that attribute in the object, if not found then finds that attribute of the class, if still not found then finds that attribute of the superclass, if still not found, it queries the __getattr__ method of that object.
In short, the order is object, class, superclasses, __getattr__.
Static vs Dynamic Typing
Dynamic Typing means the type of variables are determined at runtime (Python). On the reverse, Static Typing means assigning types to objects during the compilation process (C++).
Static Typing’s advantages:
- Earlier detection of type errors.
- More room for performance optimization.
- Code is more concise and easier to read by developers.
Dynamic Typing’s advantages:
- More flexible.
- Shorter code.
In general, Dynamic Typing is more suitable for prototyping while Static Typing is better for production code as it is faster, requires less memory, is easier to maintain, and is less prone to errors.
Python is a Dynamic Typing language, but many people try to make it more like Static Typing by using annotations and type checks.
Annotation and type check
Python allows developers to annotate types of variables in code, as below. However, it doesn’t check if the calls actually follow the annotation or not. In other words, Python treats code with and without annotation the same.
from typing import List
def push(l: List[int], v: int) -> None:
l.append(v)
To come to the rescue, there are several type-checker libraries that can help with checking types before run-time. Pytype (from Google) and Pyright (from Microsoft) are 2 options, yet the oldest and most popular one at the moment is Mypy. We can use Mypy as a command-line tool as below.
annotation-and-type-check.py:
from typing import List
def push(l: List[int], v: int) -> None:
l.append(v)
my_list = []
command line:
mypy annotation-and-type-check.py
output:
annotation-and-type-check.py:7: error: Need type annotation for "my_list" (hint: "my_list: List[<type>] = ...") Found 1 error in 1 file (checked 1 source file)
Let us try fixing this error but make another misbehavior:
annotation-and-type-check.py:
from typing import List
def push(l: List[int], v: int) -> None:
l.append(v)
my_list: List[int] = []
push(my_list, 5)
print(my_list)
push(my_list, 1.2)
print(my_list)
command line:
mypy annotation-and-type-check.py
output:
annotation-and-type-check.py:12: error: Argument 2 to "push" has incompatible type "float"; expected "int" Found 1 error in 1 file (checked 1 source file)
Strong vs Weak Typing
Weak typing means data types can be automatically converted when necessary. For example, JavaScript is a weakly typed language and it accepts 0 == '0' to be true. On the other hand, for strongly typed languages like Python, the same expression returns false.
Advantages of Weak Typing:
- It requires less effort from programmers to convert types back-and-forth.
Advantages of Strong Typing:
- Errors are caught sooner.
- Easier to understand and maintain.
- More room to optimize for time and space comsumption.
Inheritance
We should avoid subclassing built-in types (e.g. dict, list) because doing so could easily result in problems. For example, in the code below, even if we override the __setitem__ method, the new class sometimes uses this method (e.g. when assigning value with []), but sometimes it uses the old method from the parent class (e.g. when calling update).
class DoppleDict(dict):
def __setitem__(self, key, value):
super().__setitem__(key, [value] * 2)
dd = DoppleDict(one=1) # execute the old way
print("dd:", dd) # output: dd: {'one': 1}
dd["two"] = 2 # execute the new way
dd.update(three=3) # execute the old way
print("dd:", dd) # output: dd: {'one': 1, 'two': [2, 2], 'three': 3}
Multiple Inheritance
In general, Multiple Inheritance is discouraged because of its low comprehensibility. However, if we have to use it, or in cases we really need it, consider some tips below:
- Do distinguish between Interface inheritance and Implementation inheritance. Inheriting an interface creates a “is a” relationship. Inheriting from an implementation is to avoid code duplication, which usually can be replaced by composition and/or delegation.
- Use Mixins for code reuse. A Mixin is a class specially designed with bundles of methods to be reused. Mixins are not considered concrete classes and we should never instantiate an object from a Mixin. Also, name the Mixins explicitly with the Mixin suffix (e.g.
class HTMLOpMixin). - Don’t subclass more than one concrete class.
- Make Aggregate Class if needed (i.e. the class that inherits several mixins together so that future classes need only subclass this aggregate class instead of all those mixins).
- Very important: favor composition over inheritance. A composition is a class whose attributes are instances of other classes.
Iterable, iterator, and generator
The Python community almost always treats iterator and generator as synonyms.
Iterators inherit Iterable.
from collections import abc print(issubclass(abc.Iterator, abc.Iterable)) # output: True
Iterators implement the method __next__, which returns the next item in a series or StopIteration if there are no more items. Furthermore, we can only do 1 pass over each iterator.
Generators are iterators that return the expression passed to yield.
def gen_12():
yield 1
yield 2
g = gen_12()
print(next(g)) # output: 1
print(next(g)) # output: 2
print(next(g)) # output: Traceback ... StopIteration
Apart from built-in functions that return generators (e.g. zip, enumerate, range, map), the itertools module provides many other useful functions:
- Filter generators:
itertools.dropwhile(<condition>, <sequence>)(drop the first elements of the sequence while the condition results true, then take all the remaining),itertools.filterfalse(<condition>, <sequence>), etc. - Mapping generators:
itertools.accumulate(...),itertools.starmap(...), etc. - Merging generators:
itertools.zip_longest(...),itertools.chain(...), etc.
Context Manager
The with statement is designed to simplify the try/finally pattern. It creates a context in which we can do something inside, then it closes that context automatically.
The most common use case for with is when opening files.
with open(file_path, 'r') as f:
content = f.read()
Another situation is when we use with with a lock in multi-thread programming.
with some_lock:
# do something
is equivalent to:
some_lock.acquire()
try:
# do something
finally:
somelock.release()
Else block
Apart from if, elsefor, while, and try.
In these cases, similar to with if, the else block will run if the condition being checked is false:
for: when there is no remaining element in the sequence.while: when the condition is false.try: when there is no exception.
Note that the else block will NOT be executed if the main block is exited by return, break or exception caught.
Asynchrony, concurrency, and parallelism
Asynchronous programming refers to the idea that you have only 1 CPU thread having to do multiple jobs, when the job it is working on has to wait for an external resource (I/O), it changes to do another job in the meantime.
Concurrent programming also illustrates the case when you have only 1 CPU thread and there are many jobs, the only difference is that your program deliberately switches between jobs in a very fast manner, making it looks like it is doing multiple jobs at the same time even though that is not true.
Parallel programming requires you to have multiple CPU threads and either one or multiple jobs. Furthermore, you are able to really do multiple jobs at the same time (by, for example, letting each thread do one job, or letting each thread do a part of the same job).
Coroutine
Coroutine is a type of function to do asynchronous programming collaboratively. The idea is that if at some point, your function has to wait for the result of something (usually I/O with high latency), then instead of staying idle and wait, let’s hand the control back to the parent function (i.e. the function that called this function) so that the parent can do other work in the meantime.
In Python, the act of giving back control is done by the keyword await. Also, the functions that await something need to be declared async. The example below shows how we can use these keywords together with the asyncio module to run asynchronous code efficiently. Note that asyncio.sleep(0.1) at line 8 is meant to illustrate an I/O blocking operation. During that waiting time, the CPU gets to work on another task.
import time
import asyncio
results = []
async def do_some_work(num):
await asyncio.sleep(0.1)
results.append(num)
async def worker_function(name, work_list):
print(f"Execute task {name}")
for i, work in enumerate(work_list):
await do_some_work(work)
print(f"Time: {time.time() - start_time:.4f} Task {name}: done {i+1} jobs")
task_descriptions = [
("work_1", range(0, 3)),
("work_2", range(6, 10)),
]
loop = asyncio.get_event_loop()
tasks = [
loop.create_task(worker_function(task_name, work_list))
for task_name, work_list in task_descriptions
]
start_time = time.time()
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
print(results) # output: [0, 6, 1, 7, 2, 8, 9]
Output:
Execute task work_1 Execute task work_2 Time: 1.0017 Task work_1: done 1 jobs Time: 1.0019 Task work_2: done 1 jobs Time: 2.0030 Task work_1: done 2 jobs Time: 2.0033 Task work_2: done 2 jobs Time: 3.0050 Task work_1: done 3 jobs Time: 3.0052 Task work_2: done 3 jobs Time: 4.0069 Task work_2: done 4 jobs [0, 6, 1, 7, 2, 8, 9]
While in the above code, results are collected into a list results, the more formal way to get all the results returned is to use asyncio.gather:
async def do_some_work(num):
await asyncio.sleep(0.1)
results.append(num)
return num * 100
async def manager_function(task_descriptions):
outputs = await asyncio.gather(
*[
do_some_work(work)
for task_name, work_list in task_descriptions
for work in work_list
]
)
print(f"Outputs: {outputs}") # output: [0, 100, 200, 600, 700, 800, 900]
asyncio.run(manager_function(task_descriptions))
Global Interpreter Lock (GIL)
(Unfortunately) Python has a Global Interpreter Lock which prevents more than 1 thread from running simultaneously. Thus, when we use multi-threading with Python, it is actually concurrency but not parallelism. To achieve parallelism, we need to do multi-processing.
Multi-threading and Multi-processing
Normally, the main difference between multi-threading and multi-processing is that while threads can share some memory, processes don’t. However, this is not entirely true in Python. In Python, threads need to run concurrently because of the GIL, while processes can really run in parallel. Furthermore, processes are usually but not strictly forbidden from sharing memory.
The concurrent.futures supports high-level calls to achieve both multi-threading and multi-processing. Just initializing an Executor and calling executor.map(<function>, <list-of-input>) is the easiest way to do this, as below. Note that the syntax is almost entirely the same for multi-threading and multi-processing, they are only different in the type of executor, ThreadPoolExecutor and ProcessPoolExecutor.
import time
from concurrent import futures
def foo(num):
print(f"Start doing with {num}")
time.sleep(num)
print(f"Done with {num}")
return num * 10
# multi-threading
with futures.ThreadPoolExecutor(max_workers=2) as executor:
threads_results = executor.map(foo, [3, 1, 2])
print(list(threads_results)) # output: [30, 10, 20]
# multi-processing
with futures.ProcessPoolExecutor(max_workers=2) as executor:
processes_results = executor.map(foo, [3, 1, 2])
print(list(processes_results)) # output: [30, 10, 20]
output:
Start doing with 3 Start doing with 1 Done with 1 Start doing with 2 Done with 3 Done with 2 [30, 10, 20] Start doing with 3 Start doing with 1 Done with 1 Start doing with 2 Done with 3 Done with 2 [30, 10, 20]
Apart from this executor.map method, which is simple and returns the results in the order of the input, we can also use executor.submit and futures.as_complete. The advantages are:
- Different functions can be executed.
futures.as_completedcan process different types of future (e.g. you can mix threads and processes).- Faster calls will get their results first (i.e. returned result not in order). We do not have to wait for all functions to complete to get the first result.
# multi-threading
waiting_jobs = []
with futures.ThreadPoolExecutor(max_workers=2) as executor:
for inp in range(5, 0, -1):
future = executor.submit(foo, inp)
waiting_jobs.append(future)
results = []
for result in futures.as_completed(waiting_jobs):
results.append(result.result())
print(results) # output: [40, 20, 50, 10, 30]
# multi-processing
waiting_jobs = []
with futures.ProcessPoolExecutor(max_workers=2) as executor:
for inp in range(5, 0, -1):
future = executor.submit(foo, inp)
waiting_jobs.append(future)
results = []
for result in futures.as_completed(waiting_jobs):
results.append(result.result())
print(results) # output: [20, 40, 10, 30, 50]
Another library that helps with multi-processing is multiprocessing, which adds the option to share some memory between processes (although doing so is not recommended in most cases).
Dynamic attributes
Python allows for dynamic attributes, which are attributes defined at runtime.
class C:
pass
obj = C()
obj.attr_1 = "1st attribute"
Python objects save all of their attributes in their __dict__. Thus, the convenient way to add many attributes to an object is by <object>.__dict__.update(**kwargs).
obj.__dict__.update(
{"attr_2": "2nd attribute", "attr_3": 3,}
)
print(obj.__dict__) # output: {'attr_1': '1st attribute', 'attr_2': '2nd attribute', 'attr_3': 3}
print(obj.attr_3) # output: 3
Code format
Black is one of the most popular formatters. Other alternatives (or possibly complements) include isort and flake8. They ensure our code conforms to global conventions like PEP8 by not just pointing out the badly-formatted code but even automatically correcting them inline.
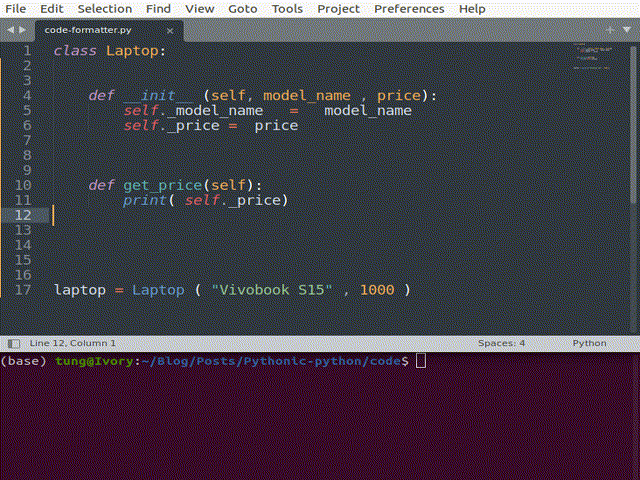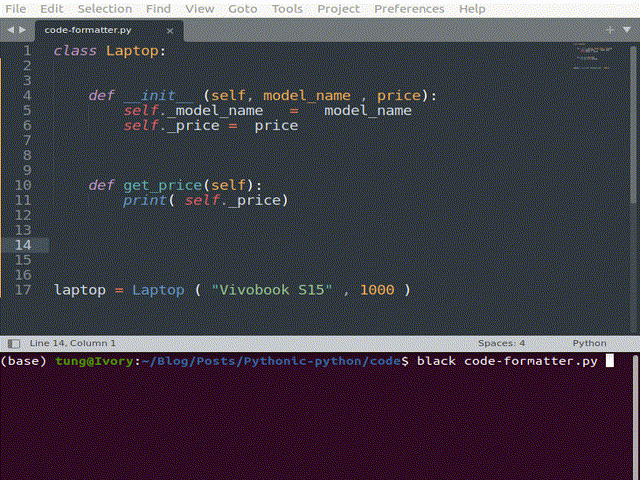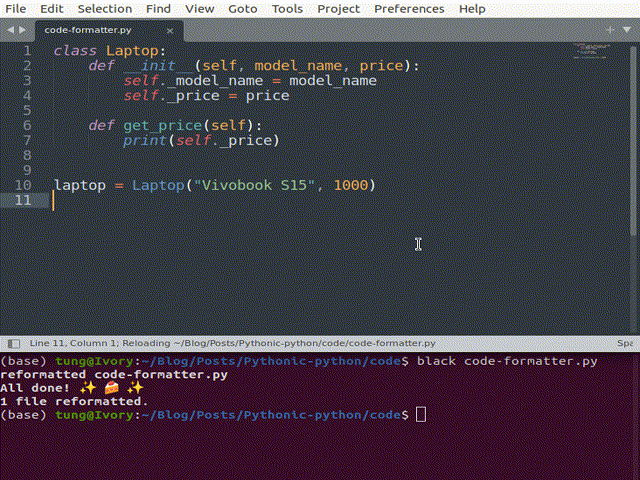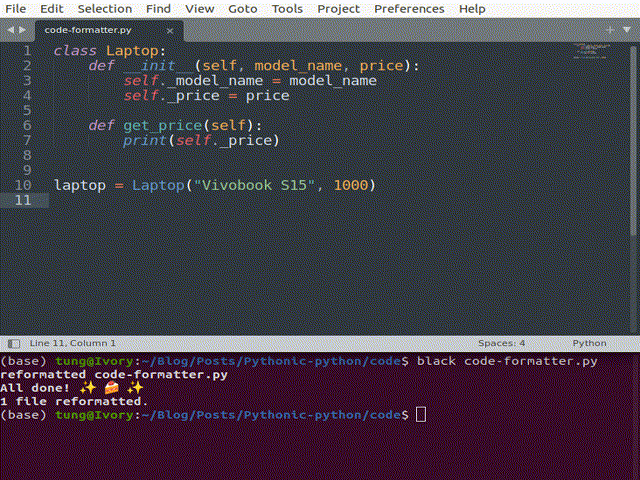
If you use notebooks, the JupyterLab Code Formatter is worth a look. It helps with stacking calls to different formatters within a button in the toolbar. Just a click on this button makes the whole notebook formatted.
All code in this post can be found in the repository.
References:
Fluent Python by Luciano Ramalho.