
It has been shown from 1998 [1] that normalization helps with optimizations, making the neural networks converge faster. However, not until 2015, when Batch Normalization [2] is published that this research direction is extensively explored by the community. Since then, many other normalization schemes have been proposed, with Weight Norm [3], Layer Norm [4], Instance Norm [5], and Group Norm [6] being the ones that get the most attention from the public. In this article, we will introduce these techniques and compare their advantages and disadvantages over each other.
Definitions
Batch Normalization
With Batch Norm, all data points of the same input mini-batch are normalized together per input dimension. In other words, for each dimension of the input, all data points in the batch are gathered and normalized with the same mean and standard deviation. Below is the transformation of BatchNorm for each separate dimension of the input x.

Note that in the case of convolutional layers, the “dimension” is perceived as the channel dimension, while in feed-forward layers, it is the feature dimension. With that to say, for example, the input data is normalized separately for each channel in a convolutional layer.
In the above algorithm,  is the sample mean of the m data points in the minibatch,
is the sample mean of the m data points in the minibatch,  is the corresponding sample variance.
is the corresponding sample variance.  and
and  are 2 parameters that are learned during Back-propagation.
are 2 parameters that are learned during Back-propagation.
A throughout discussion about BatchNorm and why it works is given in our another blog post.
Weight Normalization
Unlike BatchNorm which normalizes the neuron’s value before or after activation, WeightNorm tends to normalize the weight vectors. Even more interestingly, WeightNorm decouples the norm and value of the weight vectors. Thus, instead of learning a weight vector  , we instead learn a scalar
, we instead learn a scalar  – the norm (or informally the strength, the magnitude of the weight vector) and a vector
– the norm (or informally the strength, the magnitude of the weight vector) and a vector  – the direction of the weight vector.
– the direction of the weight vector.

While the weight vectors are used in the forward phase as usual, the backward optimization optimizes the values of and . Intuitively, this decoupling makes the norm of the parameters (i.e. the weights) more explicit,
Layer Normalization
LayerNorm uses a similar scheme to BatchNorm, however, the normalization is not applied per dimension but per data point. Put it differently, with LayerNorm, we normalize each data point separately. Moreover, each data point’s mean and variance are shared over all hidden units (i.e. neurons) of the layer. For instance, in Image processing, we normalize each image independently of any other images, the mean and variance for each image is computed over all of its pixels and channels and neurons of the layer.
Below is the formula to compute the mean and standard deviation of one data point.  indicates the current layer, H is the number of neurons in layer , and
indicates the current layer, H is the number of neurons in layer , and  is the summed input from the layer
is the summed input from the layer  to neuron
to neuron  of layer .
of layer .

Using this mean and standard deviation, the subsequent steps are the same as with BatchNorm: the input value is demeaned, then divided by standard deviation, and then affine transformed with learned and .
Instance Normalization
InstanceNorm is also a modification of BatchNorm with the only difference is that the mean and variance are not computed over the batch dimension. In other words, only the pixels in the same image and the same channel share the mean and variance of normalization. With such a restricted normalization range, the use of InstanceNorm seems to be limited in computer vision when the input is image data.
The formula is:

with H, W being the height and width of the input image. t, i, l, m are the iterators over images in the minibatch, channels, width, and height of the images, respectively. j and k also iterate over the width and height.
Group Normalization
GroupNorm is a trade-off between LayerNorm and InstanceNorm. Note that the major difference between LayerNorm and InstanceNorm is that LayerNorm does take the channel dimension into computation while InstanceNorm does not. GroupNorm, on the other hand, groups channels into groups and normalize inside each group. The batch dimension is still not used (only BatchNorm normalizes over the batch dimension).
Normalization methods comparison
In [6], the authors give a simple visualization showing the major differences among the 4 normalization methods (except WeightNorm):
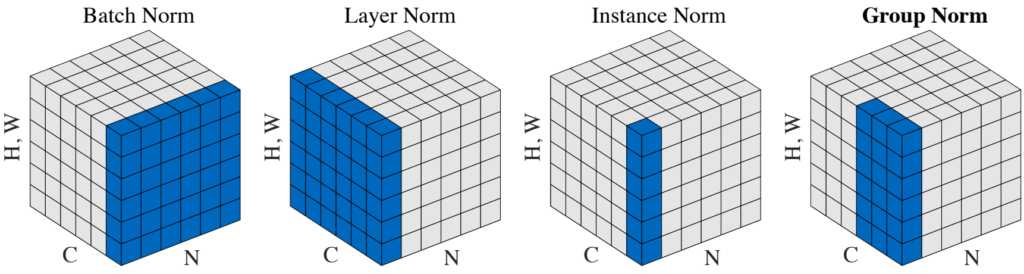
As a reminder, we recall that these 4 methods share the same structure: each value is standardized (i.e. demean and divide by standard deviation) and then reconstructed with an affine function on 2 learned scalars and .
In [4], there is a comparison of invariance properties under BatchNorm, WeightNorm and LayerNorm:

Advantages and Disadvantages
Normalization methods, in general, help with speeding-up optimization to have the network converge faster. Furthermore, they have a substantial effect on controlling gradient vanishing and exploding. Below, we examine other properties that make each of the scheme unique.
Batch Normalization
Up to the moment (early 2021), BatchNorm is usually used in state-of-the-art deep vision networks (e.g. EfficientNet).
Weight Normalization
Layer Normalization
- LayerNorm can be applied to Recurrent layers without any modifications. Since it normalizes over all dimensions except the batch dimension, LayerNorm is the method with the most number of points that share the same
 and
and  that can be simply applied to recurrent layers.
that can be simply applied to recurrent layers.
Currently, many of the state-of-the-art NLP networks are using LayerNorm (e.g. BERT and its variants, Megatron-LM).
Instance Normalization
Group Normalization
Final words
We have discussed the 5 most famous normalization methods in deep learning, including Batch, Weight, Layer, Instance, and Group Normalization. Each of these has its unique strength and advantages. While LayerNorm targets the field of NLP, the other four mostly focus on images and vision applications. There are, however, other similar techniques that have been proposed and are gaining attention from the public, for instance, Weight Standardization, Batch Renormalization, and SPADE, which we hope to cover in the next articles.
References:
- [1] Efficient BackProp: paper
- [2] Batch normalization: paper
- [3] Weight Normalization: paper
- [4] Layer Normalization: paper
- [5] Instance Normalization: paper
- [6] Group Normalization: paper
- [7] Compare BatchNorm and WeightNorm: paper
- [8] The number of parameters in a convolutional layer: answer
- [9] Instance Normalization in Image Dehazing: paper
- [10] Why BatchNorm per channel in CNN: answer