
Introduction
Deep learning is one of the buzzwords in the tech industry over the last decade. Deep learning refers to the act of doing Machine learning on deep artificial neural network architectures, which were inspired by (but not actually similar to) how human brains work. While the first neural network, the Perceptron [1], has only 2 layers for input and output, modern models may consist of tens, hundreds, or thousands of hidden layers, stacking one after the other. If we consider a model as a black-box that receives input and produces output, with Deep learning, the input has to go “deep” into the box, pass through, and be transformed at many layers before the output is produced.
From the architecture point of view, “deep” in Deep learning means a lot of layers. From the learning point of view, “deep” may mean deep reasoning. That is, for example, in an image processing model, the earlier layers often learn the raw, abstract features like edges and corners, while the later layers recognize higher-level representations like objects and people. Note, however, that deep reasoning in Deep learning does not mean making predictions by finding the “deep” causal effects from the given features.
Even though Deep learning is often referred to as one “unified” algorithm, it should rather be thought of as a paradigm of algorithms and architectures, which makes use of many layers to accomplish the learning goals. Two of the most famous variant of Deep learning are the Convolutional neural networks (CNN) and Recurrent neural networks (RNN). While their architectures are largely different, they both fall under the same umbrella of Deep learning. In the next section, we will discuss some of the renowned successes that involve different types of Deep learning.
Achievements with Deep Learning
The first event that causes the transition of the major research community from traditional Machine learning to Deep learning should be the born of AlexNet [2]. This 8-layer image classification network marked an impressive return of the neural network family with a hand-down win by a large margin in the ImageNet Large Scale Visual Recognition Challenge 2012. The AlexNet is a CNN whose most important components are a sequence of convolutional and max-pooling layers. The convolutional layers make use of weight-sharing and are responsible for extracting features. At the same time, the max-pooling layers reduce feature size and provide translation invariance. As stated in the example above, the “deepness” in Deep CNNs is mostly used for learning feature sets from low to high-level representations.
On the other hand, the Recurrent Neural Networks also create big surprises in the field of sequence modeling, as pointed out by Karpathy [3]. One of the many cool experiments Karpathy showed is the ability of the networks to write Latex sources that almost compiled. Acknowledge that the structure of Latex demands strict dependencies. A \begin needs to be followed by an \end. Moreover, \begin{X} \begin{Y} only makes sense with succeeding \end{Y} \end{X}, after a handful of words and/or math symbols in-between. While CNNs are great at capturing spatial information (i.e.width x height), the RNNs, as used in this example, are more adept at processing dependencies over time. The RNN architectures are most effective for sequential inputs like time series or texts when the prediction of an instance should also depend on past (and sometimes even future) events. In a Deep RNN, each element in the input sequence is handled by a “virtual” layer. Thus, to allow for input sequences of many elements, the networks need many “virtual” layers. These, in combination with the real, “physical” layers, result in the “deepness” of the networks.
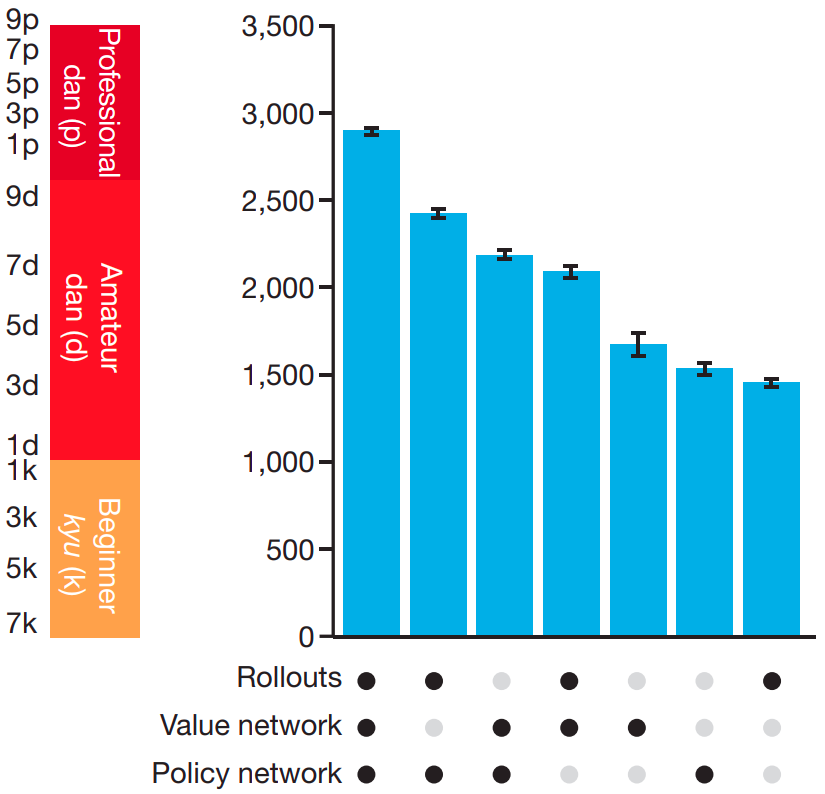
While sometimes a neural network alone could be sufficient, we may also see Deep learning models paired with other techniques to jointly address a difficult problem. One of those cases is the AlphaGo program in 2015 [4], which has gone viral for beating one of the human champions in the very sophisticated game of Go. Although AlphaGo is usually mentioned as a Deep learning’s success, it is actually a combination of Deep learning, Reinforcement learning, Monte Carlo Tree Search rollouts, and hand-crafted features by experts. The AlphaGo makes use of 2 Deep neural networks. The Policy Network was first trained with Supervised learning to predict the next moves on data of human (expert) matches and then continued with Reinforcement learning, playing against itself to improve performance. The other one, the Value Network, is a Supervised network that predicts which player will win given a board state. The Value Network is then combined with the rollouts to evaluate the positions in the tree search. Figure 1 shows how different versions of AlphaGo perform. Notice that without tree search (i.e. without rollouts and the Value network), its Elo is only roughly 1600, which is far away from its peak Elo at 2800+ and is worse than an existing commercial program name Crazy Stone, whose Elo is almost 2000 (not shown in Figure 1). It is also worth noting that hand-crafted features seem to play an important role in AlphaGo as they increase the accuracy of the Supervised learning Policy Network from 55.7% to 57%, and, said the authors, “…small improvements in accuracy led to large improvements in playing strength…”.
Putting games aside, Deep learning is also applied in more serious fields, like Bioinformatics and Drug Discovery. In 2020, Stokes et al. [5] published a paper showing how they train Deep learning to discover a new type of antibiotic. Note, however, that not all credit should be given to the network model for the discovery of the new antibiotic, as human experts also gave hands on this. According to the authors, “the success of deep neural network model-guided antibiotic discovery rests heavily on the coupling of these approaches to appropriate experimental designs.” It was humans that aided the network in designing evaluation criteria to evaluate training, cherry-pick the type of training data (and its distribution) to input into the model, and selecting tens from thousands of strongly predicted compounds for follow-up investigation. While human involvement is still needed, this was nevertheless considered a breakthrough since machines have never been considered as being creative and can create new, hard, and impactful knowledge (we have no new class of antibiotics since the 1980s [6, 7]). This work is indeed remarkable, however, it might be not as resounding as it seems since a later correction of the paper [7] revealed that this chemical compound had actually been researched before, unnoticed by the authors of this paper.
Problems of Deep Learning
Nothing is perfect. While Deep learning has contributed to lots of successes, it also has its own problems to be addressed. The most prevailing one is low (or no) interpretability. In general, networks with more than two layers (the input and output layers) are hard to interpret, left alone SOTA networks with thousand layers. When a data point is inputted into the network, its feature values have to go through a lot of stages and at each stage, they not only intertwine with each other but also are transformed by a (usually nonlinear) activation function. In the end, it becomes impossible to analyze which feature or set of features is responsible for whatever drives the value of the output.
First, interpretability is necessary for important decisions. For example, if a hospital uses a predictive model to prescribe medication for patients, the patients need to be informed why the treatments are suitable for them, or else they would likely not take the drugs.
Second, interpretability is essential for identifying the inherent problems of the model. Take the leopard print sofa [9] as an example. It turns out that all the SOTA models (at least at that time, 2015) classify an object to be a leopard (or a jaguar) only by looking at the black spotty texture of its skin but ignoring any features regarding its shape or any parts of its body. This resulted in the leopard print sofa being identified as leopard, jaguar, or other similar cat species.
Third, interpretability is essential for correcting the models when things go wrong. Also in 2015, when Google Photos mistakenly recognized black people as gorillas [8], they found no way to fix this bias and ended up with the ugly workaround of removing the Gorilla tag. If something more interpretable like Logistic regression was used in place of neural networks, the issue could be solved in minutes by adjusting the “skin color” feature which adds a lot of probability to the Gorilla label, or this scandal had not even existed at all because the problem was addressed from the time that neural network was in Google’s labs. The same argument applies to the case of the leopard print sofa mentioned above.
Forth, this Google Photos story uncovers the fact that neural nets are extremely vulnerable to biased training data and adversarial attacks. On the one hand, how neural networks “think” is different from humans, so things that seem obvious to humans might make the networks struggle. To illustrate this point, Kevin Eykholt et al. [10] were able to trick SOTA deep networks to misclassify a Stop Sign as a Speed Limit 45 by adding some artificial graffiti that is imperceptible to humans. In the field of NLP, Qi Lei et al. [11] showed that by just paraphrasing texts, a wide range of models, from Sentimental Analysis, Fake-news Detection, to Spam Filtering are tricked to give falsified results with high confidence. While the previous two papers discuss possible attacks in test-time, the work by Daniel Zügner [12] also examines how attacks by poisonous data (in training time) can take effects, placed in the context of node classification in attributed graphs. As shown by the authors, only a few changes in node features and graph structure (that go unnoticeable by preserving graphs’ important characteristics) worsen the results dramatically. Furthermore, these adversarial attacks that work in one model may even generalize to work on other SOTA models, which makes the problem extremely dangerous. A similar concern should be put over the wide spread of pre-trained models. In the last several years, when the cost of training SOTA models go beyond what individuals and small companies can afford, pre-trained models have emerged so that only big giants like Google and Facebook need to take the hardship of training while others may just clone the matured models and do a bit of fine-tuning to adapt to their downstream tasks. Imagine some pre-trained models are, deliberately or not, vulnerable to adversarial attacks, resulting in thousands of companies being affected, maybe mildly, maybe even worse.
So, are interpretability and robustness of neural networks realistic, or a pipe-dream?
Towards better Deep Learning
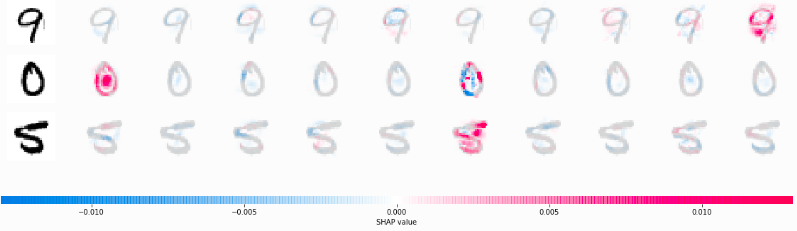
At the moment, it is clear that neural networks are not flawless. There are still (hard) fundamental problems that we have yet to know how to fully address. However, as science brings surprises, no hope should be thought of as unreal. A lot of research has been conducted targeting the weaknesses of deep neural networks (and black-box models in general). For instance, the Shap value [13], originally aimed at interpreting tabular data, now is adapted to explain the importance of pixels (in images) and words (in texts) in model predictions. Figure 2 illustrates an example of applying Shap value on predictions of a CNN on the MNIST dataset.
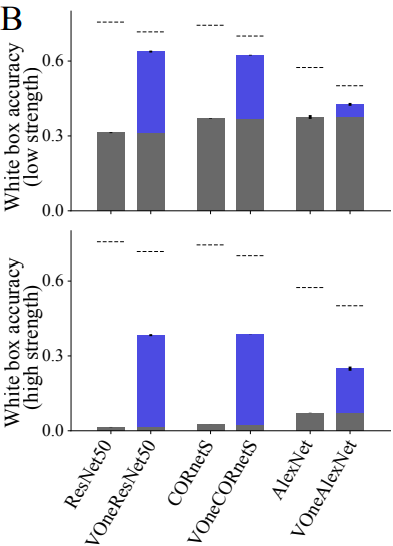
To cope with adversarial attacks, the traditional approach is adversarial training, that is, to actively find adversarial examples and re-train the neural networks on them. A novel idea, which was proposed by Joel Dapello et al. [14] is to integrate the actual biological visual cortex into the neural networks. In particular, they add to the first layer of the existing SOTA networks a Gabor filter bank with weights simulating exactly that of animals. The results look promising, as shown in Figure 3. By forcing the networks to somehow “think” the same ways living creatures think, it makes sense to hope that the networks would not make the mistakes that living creatures (or humans) do not make. This research may, potentially, pave a stone to making machines that act rationally but think humanly – maybe that is the ideal machine that we always dream of.
Another question should be, What is the relationship between Deep learning and Knowledge discovery, can they be friends or do we need to sacrifice one for the other?
We know that Deep learning is mostly black-box and black-box seems to be something opposite to extracting knowledge. However, there is some evidence that Knowledge discovery can enhance Deep learning’s performance and vice versa, Deep learning can lead to new knowledge. As mentioned above, hand-crafted features (i.e. knowledge from Go experts) have an important role in AlphaGo’s competitive strength. Similar stories also go for other Deep learning architectures. For example, the SAINT [15] is a Transformer [17] architecture neural network that predicts the correctness of students’ answers to multiple-choice questions. The SAINT+ [16] is an improvement of SAINT that makes use of two additional time-based hand-crafted features to get better performance.
On the reverse side, the research community also finds ways to extract knowledge from black-box models like neural networks. In the game of Go, the successor of AlphaGo, AlphaGo Zero [18] is said to discover new, non-standard strategies that go beyond the scope of traditional plays. This is achieved probably because AlphaGo Zero has to learn to play from scratch and is not affected by any prior knowledge. This seems to be a good sign, suggesting that Deep reinforcement learning might uncover new methods that humans couldn’t think of before, but (hopefully) can adapt to if we are aware of them. Stepping out of the Reinforcement learning environment, there are more general methods that can help with discovering new insights from supervised methods, such as Permutation Importance and the aforementioned Shap value. The idea behind Permutation Importance is very simple: to examine the importance of a feature (or a set of features together), we shuffle the values of that feature (or set of features) and see how model performance changes. If the performance is worse, those features should have contributed a lot, otherwise, they seem not much of interest. In the case of Shap value, the importance is estimated on an example-by-example basis, so it is often better for analyzing individual data points, for example, outliers.
Conclusion
We have discussed Deep learning from a macro perspective. That although Deep learning has been making and joining hands to make many breakthroughs, we must be aware that it is not magic and still there are a lot of problems to be addressed. Deep learning’s achievements are real. On average, Deep learning has helped recognition of images much more accurately, generation of texts much more fluently, gaming bots a lot stronger, and the discovery of new knowledge to take a step further. Nevertheless, it is far from being the best. The current SOTA deep models are particularly vulnerable to adversarial attacks and bias from training data. Ironically, those models are claimed to “outperform humans”, but do we actually admit that they outperform us knowing that they fall for such simple data perturbations? To be worse, even if we know what is going wrong, we have little power to correct it. Furthermore, the job of coupling Deep learning and Knowledge discovery is also a challenge. While there exist some methods that facilitate mining insights from deep models, they are not at all enough. At the moment, we can only see the tip of the iceberg.
References:
- [1] The Perceptron: A probabilistic model for information storage and organization in the brain, Rosenblatt, 1958, pdf
- [2] ImageNet Classification with Deep Convolutional Neural Networks, Krizhevsky et al., 2012, pdf
- [3] The Unreasonable Effectiveness of Recurrent Neural Networks, Karpathy, 2015, blog
- [4] Mastering the game of Go with deep neural networks and tree search, Google Deep Mind, 2015, paper
- [5] A Deep Learning Approach to Antibiotic Discovery, Jonathan M Stokes et al., 2020, pdf
- [6] Why is it so hard to develop new antibiotics?, news
- [7] Correct of A Deep Learning Approach to Antibiotic Discovery, Jonathan M Stokes et al., 2020
- [8] Google Photos labels black people as gorillas, Cutis, 2015, pdf
- [9] Suddenly a leopard print sofa appears, Khurshudov, 2015
- [10] Robust Physical-World Attacks on Deep Learning Visual Classification, Eykholt et al., 2018, pdf
- [11] Discrete Adversarial Attacks and Submodular Optimization with Applications to Text Classification, Qi Lei et al., 2019, pdf
- [12] Adversarial Attacks on Neural Networks for Graph Data, Daniel Zügner et al., 2018, pdf
- [13] Shap, website
- [14] Simulating a Primary Visual Cortex at the Front of CNNs Improves Robustness to Image Perturbations, Joel Dapello et al., 2020, pdf
- [15] Towards an Appropriate Query, Key, and Value Computation for Knowledge Tracing, Youngduck Choi et al., 2020, pdf
- [16] SAINT+: Integrating Temporal Features for EdNet Correctness Prediction, Dongmin Shin, 2020, pdf
- [17] Attention is all you need, Vaswani et al., 2017, pdf
- [18] Mastering the Game of Go without Human Knowledge, Google Deep Mind, 2017, pdf